 进城务工人员小梅
进城务工人员小梅标题:从Java中double-check机制的失效到内存模型到理解真正的线程安全(一)
文首:见微知著,以小见大,从软到硬,从Java语言到CPU晶元,用学校的书本知识联系最新科技让你顿悟,既纠正工作中高手也常犯的错误,又告诉你初级和高级Java程序员的真正区别。
摘要:本文从笔者工作中遇到的一个单例的错误实现引出了曾将较为广为讨论的double-checked locking失效问题,并对该问题背后的JSR-133内存模型进行了简单总结说明。通过本文,不了解内存模型/Java内存模型概念的人可以快速理解相应的概念,并与此前学校中已有知识结构建立联系,理解Java中包括volatile、final等关键字之所以存在的真正意义,进而明确Java中的线程安全远非锁、同步块、线程安全容器等机制,最终有利于写出真正线程安全的代码。
目录:
从Java中double-check机制的失效到内存模型到理解真正的线程安全
|– 一、究竟什么是内存模型(memory model)
|– 二、为什么需要讨论内存模型
|– 三、内存模型的三个层面
|– (1)编译器层面
|– (2)硬件平台层面
|– (3)运行时环境层面
|– 四、Java内存模型(JMM,Java Memory Model)的关键演进历程
|– 五、现代Java内存模型关键要点
|– (1)JMM的抽象
|– (2)原子性、可见性和顺序性
|– (3)数据依赖性理论
|– (4)顺序一致性理论
|– (5)内存屏障的分类
|– (6)Happens-before规则
|– 六、volatile关键字的真正含义
|– 七、synchronized关键字的真正含义
|– 八、final关键字的真正含义
|– 九、线程安全容器的真正含义
|– 十、64bit变量的原子性
|– 十一、在JDK5后使用volatile解决double-checked locking的失效问题
|– 十二、使用Initialization On Demand Holder Idiom解决double-checked locking的失效问题
|– 十三、总结
|– 十四、参考文献
———–我是分割线,以下为第一部分正文———–
近来有两个契机让笔者意识到应该写一篇文章专门讨论下Java中所谓double-checked locking(双重检查锁定)的问题,这两个契机分别是:
1)在单位组织的某一次面试中,一位面试官考察了一个涉及竞态(Rece Condition)的逻辑,并提示面试者使用double-check实现;
2)在单位组织的另一次面试中,一位面试官要求面试者手写一段单例(Singleton)实现的代码;
这两个契机让笔者意识到,很多即使有一定代码经验的程序员,在解决实际问题时往往会出于对语言运用的本能而写出double-checked locking的代码,但却往往不能意识到double-checked locking可能存在的潜在问题。探究深层次的原因时,问题的根源在一定意义上往往在于其对Java的内存模型缺乏相对深入的认知,而内存模型又是构成了并发编程的基础(即应该以何种方式和手段处理一个处理器或处理核心或线程的内存写入操作对其它处理器或处理核心或线程的可见性)——这些恰恰又是区分初/中/高级Java程序员的一个方面。
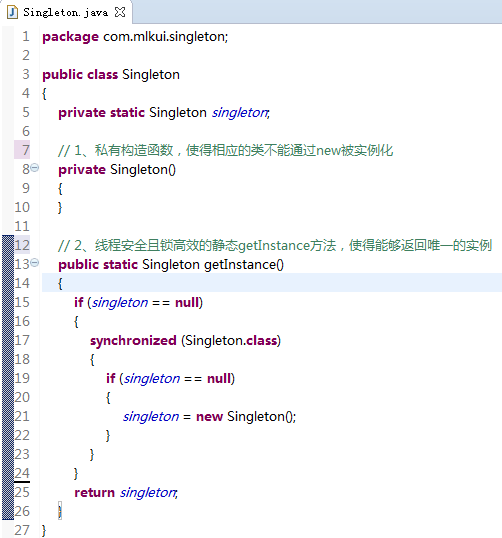
以单例的实现为例,有一位面试者就利用double-checked locking大致写出了如下的代码:
2uis.png)
单例的实现有很多种写法,不在本文的讨论范围内,但其关键往往在于两点,已在上述的代码中注释出,即:
1)私有的构造函数,使得相应的类不能通过new被实例化;
2)线程安全且锁高效的静态getInstance方法,使得能够返回唯一的实例;
因而,出于对语言运用的本能和这两点要求,一些程序员就会自然而然地写出上述示例中的代码。上述示例中的代码并不是单例最简单的写法,事实上直接实例化静态成员变量是所谓最“懒汉式”的做法,但无法做到延迟加载(Lazy Initialization),在此不再赘述。
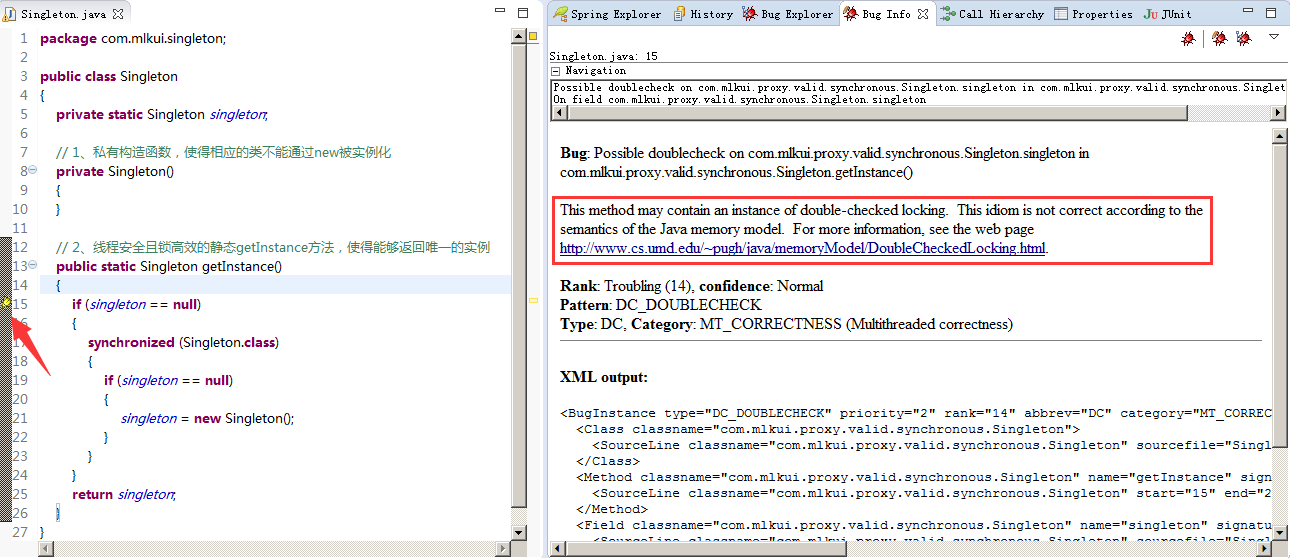
通常情况下,在不考虑使用诸如枚举或静态内部类(即所谓的Initialization on Demand Holder,后详)等的实现方式的情况下,相当一部分人甚至有一定代码经验的人都不会意识到这种写法的问题。然而,如果接触过CERT规范或习惯使用静态代码审计工具扫描自己代码的人就会发现其实上述的代码是可能存在问题的。例如,使用FindBugs就会被提示此段代码可能存在问题:
4v6]pecv0ap.png)
在FindBugs中,将这种问题描述为Possible double check of field,属于Multithreaded correctness的分类,可能导致线程安全问题,并给出了一个UMD大学的链接,其核心主旨即在于:与C++中的double-checked locking不同,对于Java而言,由于编译器优化(optimizing compilers)和内存模型(shared memory multiprocessors)等的存在,上述示例代码中的锁机制会失效(Double-Checked Locking is Broken)。
一、究竟什么是内存模型(memory model)
内存模型定义了对多个处理机/处理核心对相同地址的内存单元的写操作应该以何种规则对其它处理机/处理核心可见。在Java规范中,将这些规则统称为Semantics,即语义。
内存模型的概念最早在多处理机(multi-processer)架构中既被提出。请注意,此处的多处理机和现在多核(multi-core)概念是完全不同的,这里的多处理机正是我们在学校中计算机体系结构中的定义,在课本上根据使用主存的方式被分成了SMP(Symmetric shared-memory Multiprocessor,对称多处理机)和AMP(Asymmetric Multiprocessor,非对称多处理机)两种。在不考虑Cache的情况下,以SMP为例,多处理机架构中需要解决的问题之一就是:当两个处理器同时操作(可能是同时读、同时写、一个读一个写、一个写一个读)同一个内存地址时,在何种情况下它们才能看到相同的值。这个问题对现代的多核(multi-core)处理器而言同样存在。
近年来,随着技术的发展,出现了在一个处理机芯片上同时存在多个执行核心的多核(multi-core)架构。不管是多核(multi-core)还是多处理机(multi-processer)架构,都通常都引入了一级或多级Cache来提高执行性能(即基于程序的局部性原理,由于CPU的速度远高于RAM,因而减少CPU通过总线与RAM的直接通信可以显著提升性能)。这样,在考虑Cache的情况下,Cache的存在又引入了Cache的一致性问题(Cache Conherence),这种一致性问题既包括了多级Cache之间的一致性,也包括了Cache与主存之间的一致性,既当多个处理器/核心同时操作(可能是同时读、同时写、一个读一个写、一个写一个读)同一个内存地址时,在何种情况下它们才能在对应的本地Cache、共享Cache和内存中看到相同的值。
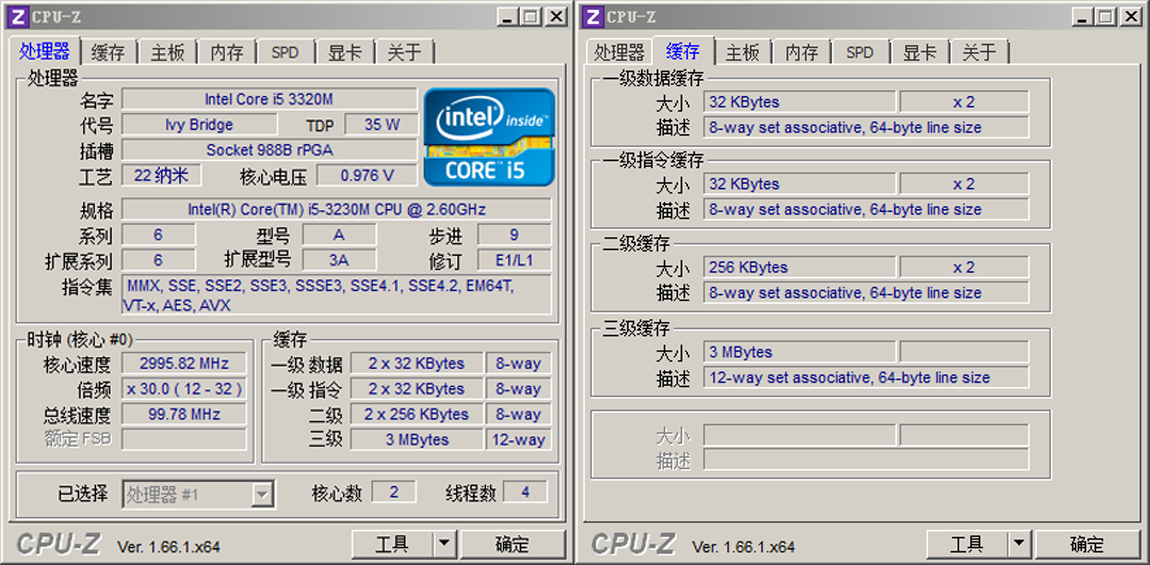
事实上,日常工作中我们经常可以看到这些多级缓存的身影,以笔者的ThinkPad T430s笔记本上所使用的Intel Core i5 3320M处理器为例,共有三级缓存,包括了32KB的一级数据缓存、32KB的一级指令缓存、256KB的二级缓存和3MB的三级缓存,如下图所示:

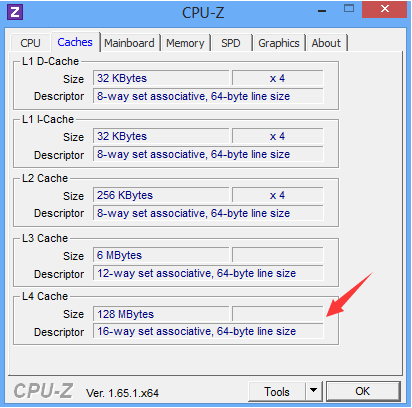
如果想搞清楚究竟什么是“8-way set associative”可以参考《Memory Barriers: a Hardware View for Software Hackers》。在某些高端处理器中可能还有四级缓存:

通常情况下, L1和L2缓存均是每个核心独享的,而L3和L4缓存由所有核心共享,这往往可以通过CPU的晶元结构观察到:
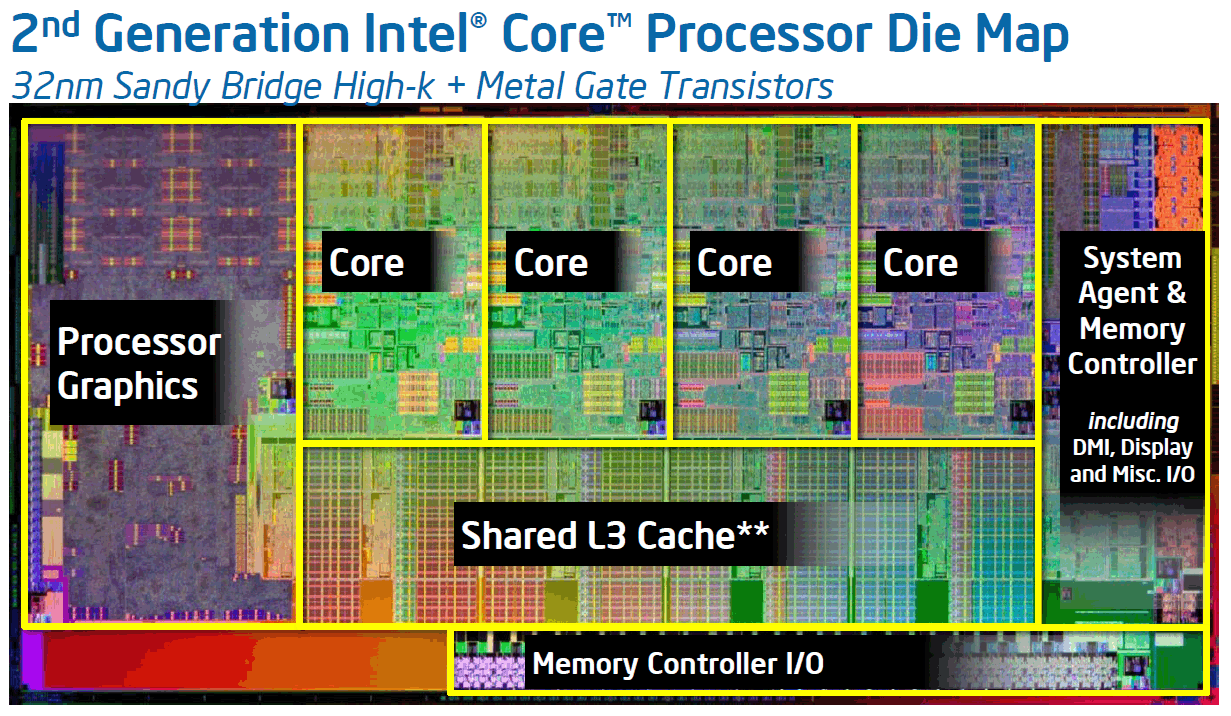

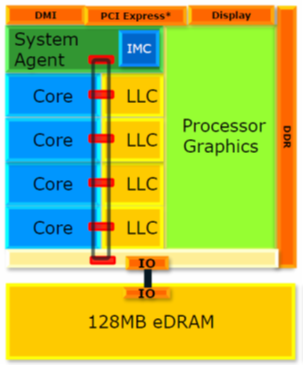
上图是因特尔32纳米SandyBridge架构酷睿处理器的晶元结构(世界上第一款将GPU图形核心将与CPU处理核心完全融为一体的处理器),其原图中只明确标识出了共享的L3缓存,而没有标识出L1和L2缓存,实际上L1(又分为数据缓存DC和指令缓存IC)和L2是每个Core独享的,如下图所示:
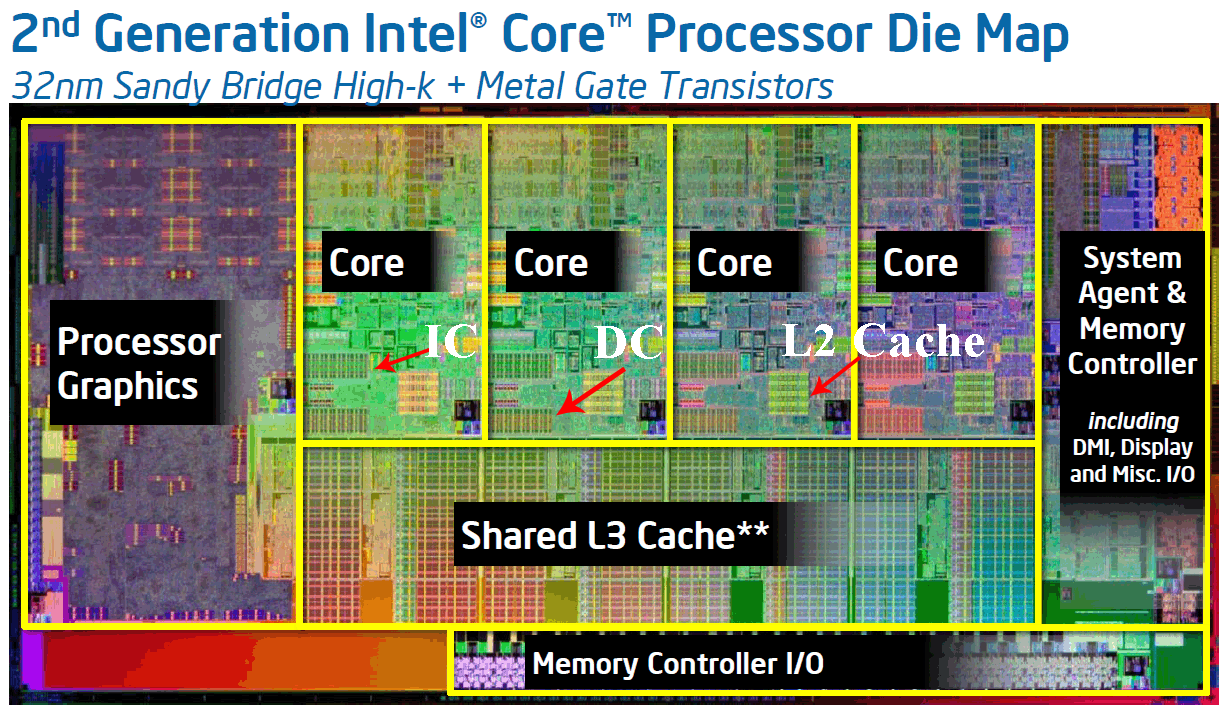

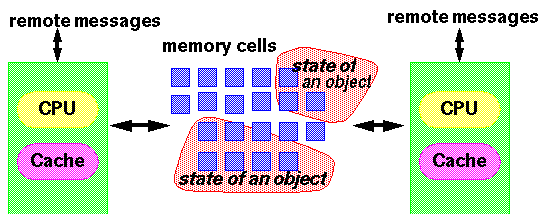
这样,也就很容易理解了,在真正的并发情况下(不考虑单核的时间片轮转和Hyper-thread超线程),一旦多个Core中的同时执行的不同线程读写到同一块内存单元,就自然地既涉及到了Core–>多级Cache–>内存单元之间的一致性问题,也涉及到了多个Core在何种情况下才能看到相同的值的问题,大意如下图所示:

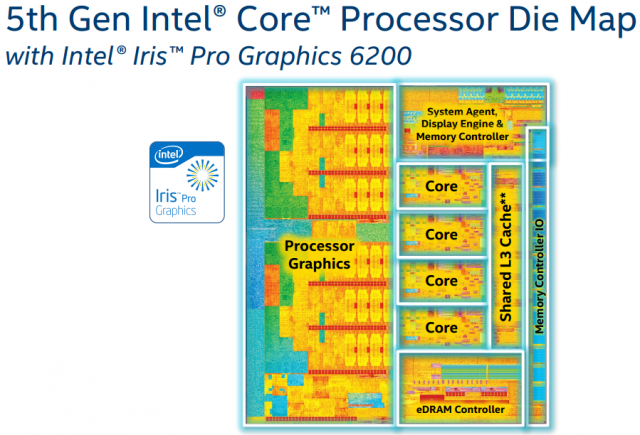
稍微拓展一下,对于上文提到的L4缓存,主要用于解决GPU(图形核心)和CPU(处理器核心)之间交换数据的问题,称为eDRAM。在之前第二代酷睿SandyBridge的晶元结构中,我们可以明显看到图形核心并没有独立的显存,只能共享内存空间,因而限制了图形核心的性能和效率。而通过在CPU和GPU之间增加了128MB的eDRAM,为GPU与CPU之间的数据交互计算中减少与主存的交互提供了可能,效率更高(高到什么程度可以参考2016年5月Intel Xeon E3-1500 v5发布时吹的牛B)。如下图所示,可在晶元结构中看到eDRAM控制器及eDRAM本身所占的面积甚至超过了一个CPU Core的大小,也远大于L3缓存所占的面积:

该晶元结构所对应的逻辑结构如下图所示,请注意图中Core之间的总线形式,正如教科书上所说的一样,这也决定了Cache一致性机制的实现方式(Cache-coherence Protocol),学过计算机组成原理的同学一定会把记忆深处的知识马上联系起来,在此不再赘述(可参考《Memory Barriers: a Hardware View for Software Hackers》,现代CPU架构一般是用MESI协议保证,其中Intel使用MESI,AMD使用MOESI):

二、为什么需要讨论内存模型
Java作为一种高级语言,在很多开发者眼中根本意识不到内存模型的存在,尤其是对底层和编译器缺乏认识的开发者看来可能更加晦涩。例如,对于不曾阅读过《IA-32 Architectures Software Developer’s Manuals》及《程序员的自我修养》的开发者就很可能由于完全不能想象出高级语言中的一条语句究竟是如何在CPU中执行的(事实上也早已远远超出了编译原理等书本上学到的知识^_^),而导致难以接受。
在笔者看来,正如嵌入式让笔者了解了这个世界上很多东西(比如手机、机顶盒及无数的各种其他嵌入式设备,对于了解嵌入式的人看来仅仅是一堆零件外加操作系统和运行在操作系统上的应用而已)的运行原理一样,理解内存模型也是理解Java中包括volatile、final等关键字之所以存在的原因、理解真正的线程安全并最终写出线程安全代码的关键,更是区分初/中/高级Java程序员的重要分水岭。
在UMD的文章中也明确回答了Why should you care的问题:Why should you care? Concurrency bugs are very difficult to debug. They often don’t appear in testing, waiting instead until your program is run under heavy load, and are hard to reproduce and trap. You are much better off spending the extra effort ahead of time to ensure that your program is properly synchronized; while this is not easy, it’s a lot easier than trying to debug a badly synchronized application.
理解事物运行的原理是人类对知识追求的最初冲动和根本目标,也是在将来建立更深认识并得以在相关领域走得更深更远的坚实基础。Java中的线程安全问题(老外也经常称之为synchronization问题)远非锁、同步块、线程安全容器等机制,不了解Java的内存模型就根本谈不上彻底理解线程安全问题,离所谓的高级Java程序员更是相去甚远,也很可能在编码的过程中埋下诡异的巨坑,给职业生涯留下遗憾。
三、内存模型的三个层面
内存模型是一个同时涉及到了编译器、运行时环境和硬件平台的概念,并与可能发生在多个层面上的指令重排序(Reordering)有重要关联。
在现代计算机体系结构中,为了提高程序的执行性能,编译器和处理器会分别从软件层面和硬件层面对指令做重排序,以在不改变程序执行结果的前提下尽可能快得执行(Compilers, processors, and caches are free to take all sorts of liberties with our programs and data, as long as they don’t affect the result of the computation)。我们必须认识到,内存模型所涉及的诸多概念很多是反直觉的(counterintuitive,该词在规范中大量出现),例如表面上看上去是顺序执行的高级语言的语句实际上是非顺序执行的。
(1)编译器层面
按照多数高级语言的规范,编译器可以在不改变单线程程序语义的前提下,重新组织高级语言语句的执行顺序。对于Java这种涉及字节码的语言,在编译器层面的重排序既可能发生在源代码(Source Code)到字节码(Java Bytecode)的过程,也可能也发生在JVM执行引擎(Execution Engine)的JIT(Just In Time)通过即时编译将部分字节码编译为本地代码(Native Code)的过程中。
编译器层面的指令重排序解释了本文开头示例代码之所以错误的原因,进而也解释了Java中double-checked locking之所以失效的原因。可以想象,对于示例中的赋值语句:


在逻辑上实际包含了至少三个步骤,即:
1)申请一片内存,将该片内存的起始地址记为p;
2)将p所指向的内存区域实例化为一个新的Singleton对象;
3)将新实例化出的Singleton对象所在地址(即p的值)赋值给变量singleton;
根据《Java Language Specification》的规范,Java的编译器和JIT编译器可以在不改变单线程程序语义(as-if-serial semantics)的前提下重排上述三个步骤的执行顺序,即只要能够得到与严格顺序执行环境下相同的结果,指令的执行顺序就可以被重排(So long as you achieve the same result as you would have if the instructions were executed in a strictly sequential environment),如下图所示: 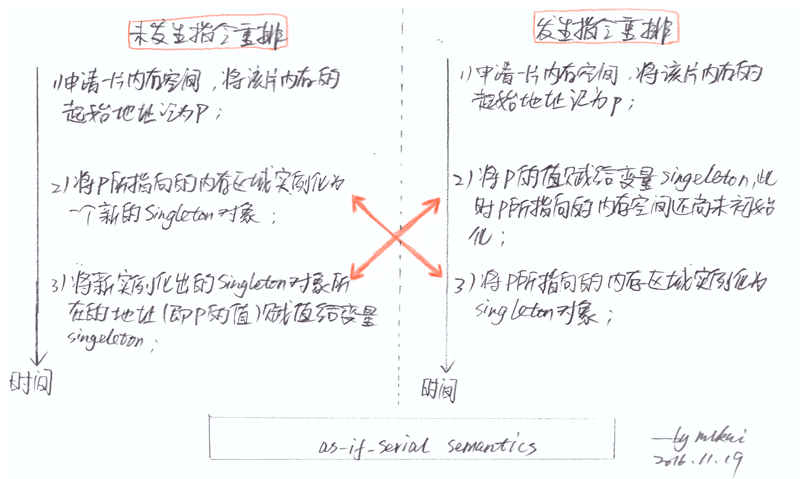 上述重排原则之所以成立的根本原因在于:在单线程/顺序执行环境下,当申请了一片内存后,不管是先将该片内存的起始地址p赋给变量singleton,然后再初始化p所指向的内存区域;还是当申请了一片内存后,先初始化p所指向的内存区域,再将该片内存的起始地址p赋给变量singleton,在单线程/顺序执行环境下函数执行完成退出时所得到的执行效果一致!不管是编译器还是JIT编译器,都可能出于各种理由对上述的赋值逻辑进行重排。对于示例中的代码,请注意,即便此处使用了synchronized同步块,却锁不住最外层的if语句:
上述重排原则之所以成立的根本原因在于:在单线程/顺序执行环境下,当申请了一片内存后,不管是先将该片内存的起始地址p赋给变量singleton,然后再初始化p所指向的内存区域;还是当申请了一片内存后,先初始化p所指向的内存区域,再将该片内存的起始地址p赋给变量singleton,在单线程/顺序执行环境下函数执行完成退出时所得到的执行效果一致!不管是编译器还是JIT编译器,都可能出于各种理由对上述的赋值逻辑进行重排。对于示例中的代码,请注意,即便此处使用了synchronized同步块,却锁不住最外层的if语句:
上述重排原则之所以成立的根本原因在于:在单线程/顺序执行环境下,当申请了一片内存后,不管是先将该片内存的起始地址p赋给变量singleton,然后再初始化p所指向的内存区域;还是当申请了一片内存后,先初始化p所指向的内存区域,再将该片内存的起始地址p赋给变量singleton,在单线程/顺序执行环境下函数执行完成退出时所得到的执行效果一致!不管是编译器还是JIT编译器,都可能出于各种理由对上述的赋值逻辑进行重排。对于示例中的代码,请注意,即便此处使用了synchronized同步块,却锁不住最外层的if语句: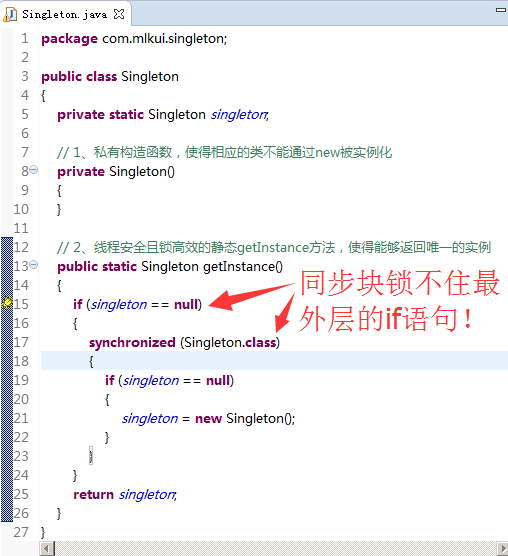

因此,在并发情况下,一旦发生指令重排序,某些线程很可能读到了已经被赋值但尚未完成实例化的对象,如下图所示:
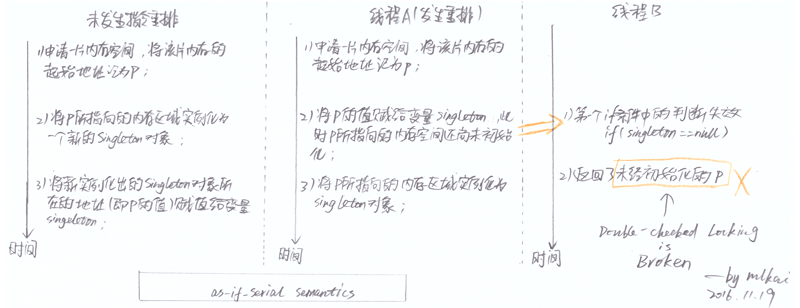 图中,线程A按照正常逻辑锁住并进入了同步块,申请了一片起始地址记为p的内存,由于指令重排的存在将p赋值给了变量singleton。此时,线程B开始执行,由于同步块锁不住第一个if语句且p已经被赋值(即singleton != null),因而线程B拿到了一个刚刚被分配空间但还没有完成初始化操作的对象(The writes which initialize singleton and the write to the singleton field can be reordered by the compiler or the cache, which would have the effect of returning what appears to be a partially constructed SOMETHING. The result would be that we read an uninitialized object.)。
图中,线程A按照正常逻辑锁住并进入了同步块,申请了一片起始地址记为p的内存,由于指令重排的存在将p赋值给了变量singleton。此时,线程B开始执行,由于同步块锁不住第一个if语句且p已经被赋值(即singleton != null),因而线程B拿到了一个刚刚被分配空间但还没有完成初始化操作的对象(The writes which initialize singleton and the write to the singleton field can be reordered by the compiler or the cache, which would have the effect of returning what appears to be a partially constructed SOMETHING. The result would be that we read an uninitialized object.)。 有关指令重排可以通过反编译器、反汇编器对中间代码/字节码/可执行代码等验证,在此不再赘述。由于我们通常只是应用开发人员,所以一般只从逻辑上建立基本的认知即可,不信邪的或者有兴趣的可以自行验证(后续有专门的章节讲述如何验证)。
(2)硬件平台层面
硬件平台层面通常又分为处理器(processor)和存储系统(memory system)两个维度,其中:
1)处理器维度。正如教科书上所说,现代处理器的一个处理核心内部通常包含了多条流水线,每个流水线上又有诸如译码、算术运算、逻辑运算等执行单元(即N级流水线),这些执行单元是并行执行的,从而实现了指令集并行(Instruction Level Parallelism)。同样,像教科书上所说的一样,分支条件、数据依赖等问题会打破流水线的执行,因而处理器还会使用乱序执行(Out of Order Execution)以提高处理器性能。事实上,对于Intel x86架构而言,从Pentium Pro(奔腾系列)以后的所有处理器均支持乱序执行。因此,从处理器层面讲指令本身就是可能被乱序执行的。
2)存储系统维度。与教科书上对存储的描述一致,在不考虑外存时,存储系统通常包括“CPU-Cache-主存”三级。在这三级存储系统中,各级的存储器控制器或机制常常会将对某个变量所对应内存单元的写入操作进行重新排序,从而使得这些写入操作可能与其他运算或内存操作指令同时进行,甚至在某些情况下这些写操作压根不会发生。
内存模型正是需要解决上述的可见性问题,大致上分为强内存模型(strong memory model)和弱内存模型(weaker memory model)两种,其中:
1)强内存模型,在任意情况下,同一地址的内存中的值对所有处理器/核心均一致;
2)弱内存模型,通过特定的内存屏障(memory barrier/fence)指令,通过对处理器/核心本地Cache的flush和invalidte操作实现一个处理器的写操作被其他处理器可见。内存屏障通常在lock和unlock操作时同时进行,当然这种操作对于对高级语言是透明的。
与教科书上所学到的简单一级缓存不同,在现代计算机体系结构中,硬件层面的内存模型除了Load和Store外,通常还包括了WC(Write-combining,合并写,通常在L1缓存Miss时使用)操作。例如,下图是一个简化的现代多核CPU,从上图可以看出执行单元、本地寄存器、本地一级缓存、本地二级缓存和共享三级缓存,处理核心会利用Load、Store和Write-combining操作Cache和主存:
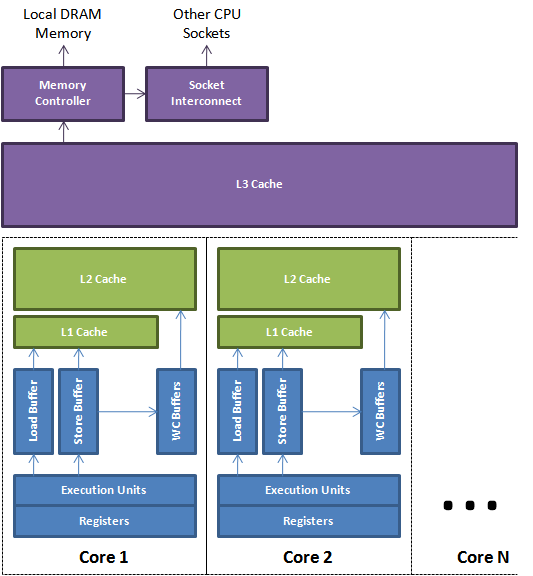

此处所包含的知识点远远超过了本文可能的篇幅和重点,受限于笔者的能力对于此处的理解也不到位,在此不再赘述,有兴趣的读者可以仔细阅读IA32的手册,其大意就是通过Store Barrier、Load Barrier和Full Barrier、Lock、Unlock来实现数据在各级存储之间的同步。
(3)运行时环境层面
很多程序员根本理解不了运行时环境/运行时库这个基本的概念。
事实上,运行时环境层面解释了为什么C和C++没有内存模型的概念,这主要是由于C和C++语言本身就是不支持多线程的,这两门语言对于多线程的实现是由编译器、多线程运行时环境(例如POSIX标准的pthread库)和所依赖的具体硬件平台共同保证的。Java defines its relationship to the underlying hardware through a formal memory model that is expected to hold on all Java platforms, enabling Java’s promise of “Write Once, Run Anywhere”. By comparison, other languages like C and C++ lack a formal memory model; in such languages, programs inherit the memory model of the hardware platform on which the program runs.
例如,从事过Windows开发的程序员经常看到如下图示的运行时库:
%5BFU%252DHB8B)PLC.png)
四、Java内存模型(JMM,Java Memory Model)的关键演进历程
Java是首次尝试在语言规范层面定义能够在异构处理器架构下运行的内存模型语义的高级语言。与内存模型的定义类似,JMM就是Java语言,尝试从语言规范的层面而非硬件平台层面,解决多个线程对相同地址的内存单元的写操作应该以何种规则对其它线程可见而定义的一套与具体处理器架构无关的语义。事实证明,这是一件超过了预期的、非常复杂、难以理解、也是重度实现相关的事。
1997年前,Java内存模型还存在着很多严重的问题,诸如final、volatile的描述和实现都是诡异、反直觉甚至无法实现的。直到1997年后,JDK5,才在JSR-133《Java Memory Model and Thread Specification Revision》中对Java内存模型进行了修改,解决了此前的各种含糊不清的问题,使得final、volatile和synchronized等涉及线程安全的行为满足了应用程序员的一般直觉(intuitive framework),即:
1)volatile,与C语言中类似,一定意义上的禁止编译器优化,使得所有对volatile变量的读写操作立即在主存中原子性地生效,并使得写操作立即对所有其他线程可见(对一个volatile变量的读总是能看到任意线程对这个volatile变量最后写入的结果);
2)synchronized,除实现互斥外,将可能涉及变量的值向寄存器和各级缓存中读出或写入;
3)final,final类型的成员变量的值永远是统一的一个,不应该在类初始化期间得到不同的值;
除了上述重要的三点外,JSR-133还引入了initialization safety的概念并一直延续到今天,也就是现在经常提到的实例化锁。
五、现代Java内存模型关键要点
JMM是JVM实现Write once, run anywhere的重要基础。对于Java开发人员而言,一般并不需要关心诸如缓存一致性协议、内存屏障等平台相关的底层细节,但有一定认知的程序员一定可以想象到,在JVM中应该有某种机制完成了Java内存模型到硬件内存模型的转换,这种机制恰恰正是由JMM在底层通过使用内存屏障等机制完成的。正如前文所述,从Java源代码到最终实际执行的机器指令序列,一般会编译器、处理器、存储系统三个层级的重排序,这些重排序都可能会导致多线程程序出现内存可见性问题。JMM作为语言规范层面的内存模型,主要是通过禁止特定类型的编译器重排序和处理器重排序来为程序员提供符合直觉的和可预测的内存可见性(JMM allows the kinds of manipulations listed above, but bounds their potential effects on execution semantics and additionally points to some techniques programmers can use to control some aspects of these semantics),其中:
1)对于编译器层面,JMM通过禁止特定类型的编译器重排序实现;
2)对于处理器和存储系统层面,JMM通过在生成指令序列中插入特定类型的内存屏障(Memory Barriers,在IA架构中称为Memory Fence,即sfence、ifence和mfence)指令实现;
在一定意义上,JMM的所有抽象都是由正确的组合memory barriers来实现的。JMM确保了在同样的Java代码能够在不同的处理器架构下实现相同的内存可见性逻辑。
(1)JMM的抽象
通过本文的前述内容,大家应该可以看出JMM其所涉及的概念不是为程序员所熟悉的类、对象、方法等概念;相反,JMM定义的是线程和主内存之间的抽象关系(JMM defines an abstract relation between threads and main memory)。在JMM的抽象中,每个线程都有一个对应的工作内存(working memory),如下图所示:
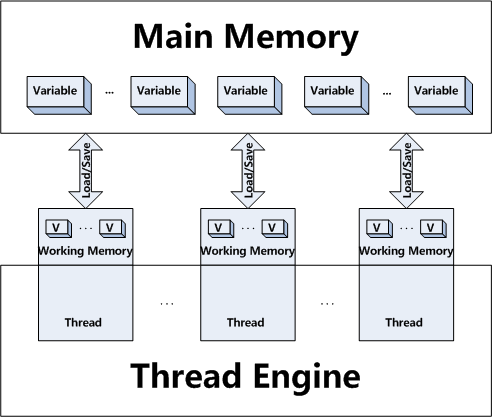

工作内存是JMM中的一个抽象概念并不真实存在,是对用来存储值的Cache和寄存器的一种抽象(Every thread is defined to have a working memory (an abstraction of caches and registers) in which to store values)。JVM是基于栈的虚拟机(请注意安卓上的dalvik实现是基于寄存器的虚拟机),在Java中,所有对象实例、静态实例和数组元素存储在堆内存中,堆内存在线程之间共享,因而存在内存的可见性问题,受内存模型的影响,如下图中最左边所示:
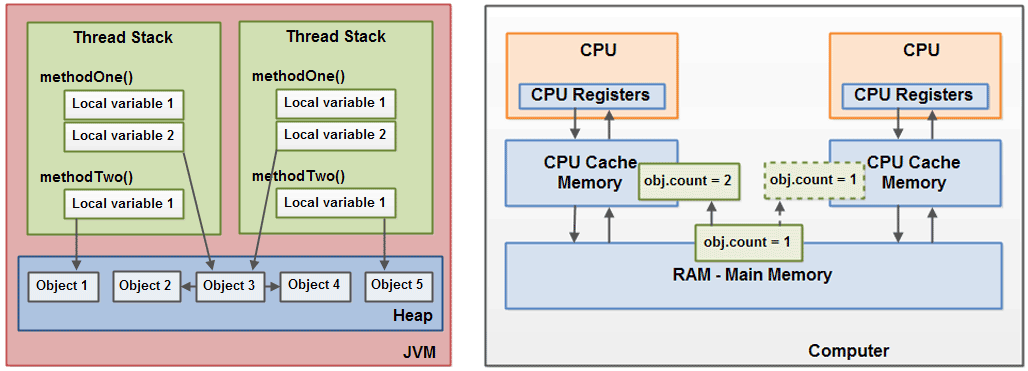

对于Java而言,JMM所定义的语义大部分正是用来定义在何种情况下值应该在主存和每个线程的工作内存之间同步(Most rules are phrased in terms of when values must be transferred between the main memory and per-thread working memory)。例如,在上图中最右边,两个线程的本地内存A和B有主存中共享变量obj.count的副本。假设线程A在执行时将obj.count的值更新为2并临时存放在自己的本地工作内存A中,那么除非它因为某些条件发生(例如volatile、同步块等)时将自己本地工作内存A中修改后的值2刷新到主存中,否则线程B到仍然只能读到其本地工作内存中的值1。这样,从整体来看,同步过程可以看做是线程A在向线程B发送消息,而且这个通信过程必须要经过主存,因而JMM正是通过控制主存与每个线程的本地工作内存之间的交互为Java程序员提供内存可见性的保证。
———–我是分割线,第一部分完,敬请期待———–
目录:
从Java中double-check机制的失效到内存模型到理解真正的线程安全
|– 一、究竟什么是内存模型(memory model)
|– 二、为什么需要讨论内存模型
|– 三、内存模型的三个层面
|– (1)编译器层面
|– (2)硬件平台层面
|– (3)运行时环境层面
|– 四、Java内存模型(JMM,Java Memory Model)的关键演进历程
|– 五、现代Java内存模型关键要点
|– (1)JMM的抽象
|– (2)原子性、可见性和顺序性
|– (3)数据依赖性理论
|– (4)顺序一致性理论
|– (5)内存屏障的分类
|– (6)Happens-before规则
|– 六、volatile关键字的真正含义
|– 七、synchronized关键字的真正含义
|– 八、final关键字的真正含义
|– 九、线程安全容器的真正含义
|– 十、64bit变量的原子性
|– 十一、在JDK5后使用volatile解决double-checked locking的失效问题
|– 十二、使用Initialization On Demand Holder Idiom解决double-checked locking的失效问题
|– 十三、总结
|– 十四、参考文献
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » 从Java中double-check机制的失效到内存模型到理解真正的线程安全(一)
是真正的大佬,从上到下讲的很好,