 进城务工人员小梅
进城务工人员小梅If you are looking for a language detector / language guesser library in Java, this seems to be the best open source library you can get at this time.
②当输入文本包含多种语言时,默认算法有问题。此时,可以试着把文本(句子或段落)分开,并检测各个部分。即使在最好的情况下,对整段文本进行识别也只能得到占据主要部分的语言;
③当输入文本不符合预期(和支持)的语言时,不能很好地处理。例如,如果只加载包括英语和德语的配置文件,但输入文本是用法语写的,那么输出要么是更可能的一个,要么是无法判断。
language-detector默认支持71种语言(使用ISO 639 Language Codes标准)如下表所示,常见的语言应该都包含在内了。有些需要使用诡异编码的语言,不支持也罢:
| 1 | af | 南非荷兰语 |
| 2 | an | 阿拉贡语 |
| 3 | ar | 阿拉伯语 |
| 4 | ast | 阿斯图里亚斯语 |
| 5 | be | 白俄罗斯语 |
| 6 | br | 布兰顿语 |
| 7 | ca | 加泰罗尼亚语 |
| 8 | bg | 保加利亚语 |
| 9 | bn | 孟加拉语 |
| 10 | cs | 捷克语 |
| 11 | cy | 威尔士语 |
| 12 | da | 丹麦语 |
| 13 | de | 德语 |
| 14 | el | 希腊语 |
| 15 | en | 英语 |
| 16 | es | 西班牙语 |
| 17 | et | 爱沙尼亚语 |
| 18 | eu | 巴斯克语 |
| 19 | fa | 波斯语 |
| 20 | fi | 芬兰语 |
| 21 | fr | 法语 |
| 22 | ga | 爱尔兰语 |
| 23 | gl | 加利西亚语 |
| 24 | gu | 古吉拉特语 |
| 25 | he | 希伯来语 |
| 26 | hi | 印地语 |
| 27 | hr | 克罗地亚语 |
| 28 | ht | 海地语 |
| 29 | hu | 匈牙利语 |
| 30 | id | 印尼语 |
| 31 | is | 冰岛语 |
| 32 | it | 意大利语 |
| 33 | ja | 日语 |
| 34 | km | 高棉语 |
| 35 | kn | 卡纳达语 |
| 36 | ko | 韩国语 |
| 37 | lt | 立陶宛语 |
| 38 | lv | 拉脱维亚语 |
| 39 | mk | 马其顿语 |
| 40 | ml | 马拉雅拉姆语 |
| 41 | mr | 马拉语 |
| 42 | ms | 马来语 |
| 43 | mt | 马耳他语 |
| 44 | ne | 尼泊尔语 |
| 45 | nl | 荷兰语 |
| 46 | no | 挪威语 |
| 47 | oc | 奥克语 |
| 48 | pa | 旁遮普语 |
| 49 | pl | 波兰语 |
| 50 | pt | 葡萄牙语 |
| 51 | ro | 罗马尼亚语 |
| 52 | ru | 俄语 |
| 53 | sk | 斯洛伐克语 |
| 54 | sl | 斯洛文尼亚语 |
| 55 | so | 索马里语 |
| 56 | sq | 阿尔巴尼亚语 |
| 57 | sr | 塞尔维亚语 |
| 58 | sv | 瑞典语 |
| 59 | sw | 斯瓦希里语 |
| 60 | ta | 泰米尔语 |
| 61 | te | 泰卢固语 |
| 62 | th | 泰语 |
| 63 | tl | 他加禄语 |
| 64 | tr | 土耳其语 |
| 65 | uk | 乌克兰语 |
| 66 | ur | 乌尔都语 |
| 67 | vi | 越南语 |
| 68 | wa | 瓦隆语 |
| 69 | yi | 意第绪语 |
| 70 | zh-cn | 简体中文 |
| 71 | zh-tw | 繁体中文 |
language-detector位于Maven中央仓库中,其地址为http://mvnrepository.com/artifact/com.optimaize.languagedetector/language-detector,目前共有三个版本:
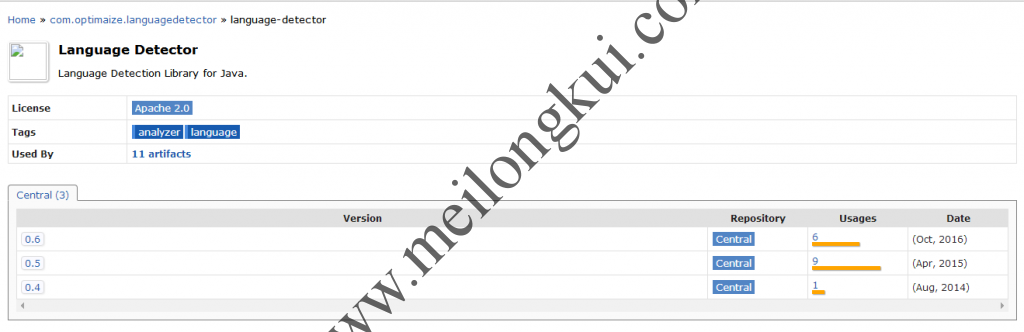
com.optimaize.languagedetector
<dependency>
<groupId>com.optimaize.languagedetector</groupId>
<artifactId>language-detector</artifactId>
<version>0.6</version>
</dependency>
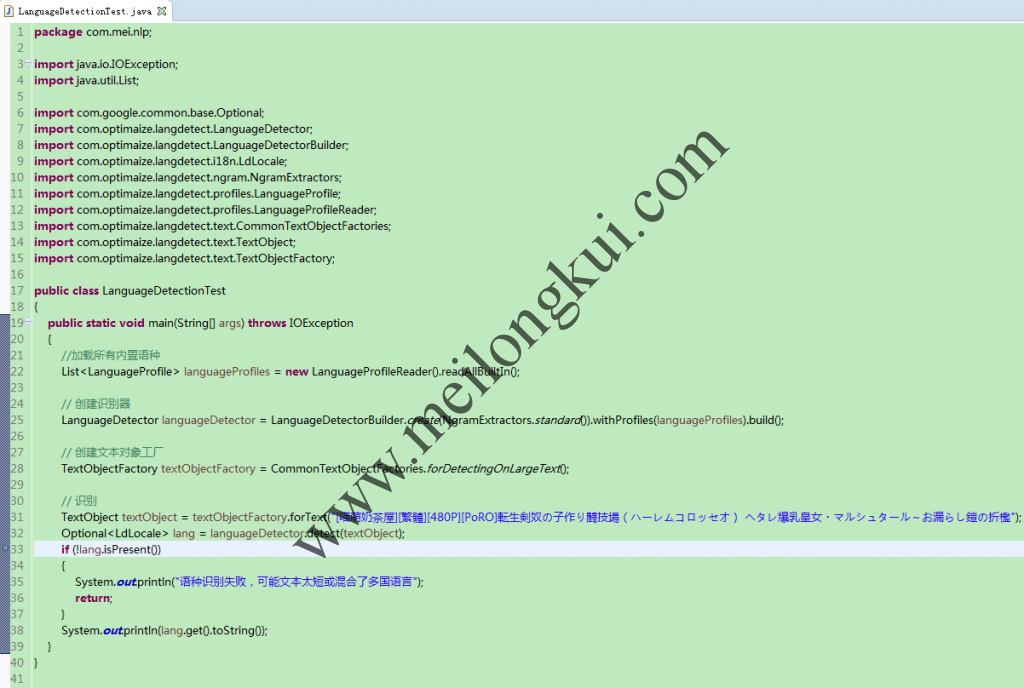
在Java中使用language-detector进行语种识别
根据文档,直接加载全部内置语言需要75MB的内存,对应代码如下:
package com.mei.nlp;
import java.io.IOException;
import java.util.List;import com.google.common.base.Optional;
import com.optimaize.langdetect.LanguageDetector;
import com.optimaize.langdetect.LanguageDetectorBuilder;
import com.optimaize.langdetect.i18n.LdLocale;
import com.optimaize.langdetect.ngram.NgramExtractors;
import com.optimaize.langdetect.profiles.LanguageProfile;
import com.optimaize.langdetect.profiles.LanguageProfileReader;
import com.optimaize.langdetect.text.CommonTextObjectFactories;
import com.optimaize.langdetect.text.TextObject;
import com.optimaize.langdetect.text.TextObjectFactory;public class LanguageDetectionTest
{
public static void main(String[] args) throws IOException
{
//加载所有内置语种
List<LanguageProfile> languageProfiles = new LanguageProfileReader().readAllBuiltIn();// 创建识别器
LanguageDetector languageDetector = LanguageDetectorBuilder.create(NgramExtractors.standard()).withProfiles(languageProfiles).build();// 创建文本对象工厂
TextObjectFactory textObjectFactory = CommonTextObjectFactories.forDetectingOnLargeText();// 识别
TextObject textObject = textObjectFactory.forText(“[喵萌奶茶屋][繁體][480P][PoRO]転生剣奴の子作り闘技場(ハーレムコロッセオ) ヘタレ爆乳皇女・マルシュタール~お漏らし鎧の折檻”);
Optional<LdLocale> lang = languageDetector.detect(textObject);
if (!lang.isPresent())
{
System.out.println(“语种识别失败,可能文本太短或混合了多国语言”);
return;
}
System.out.println(lang.get().toString());
}
}
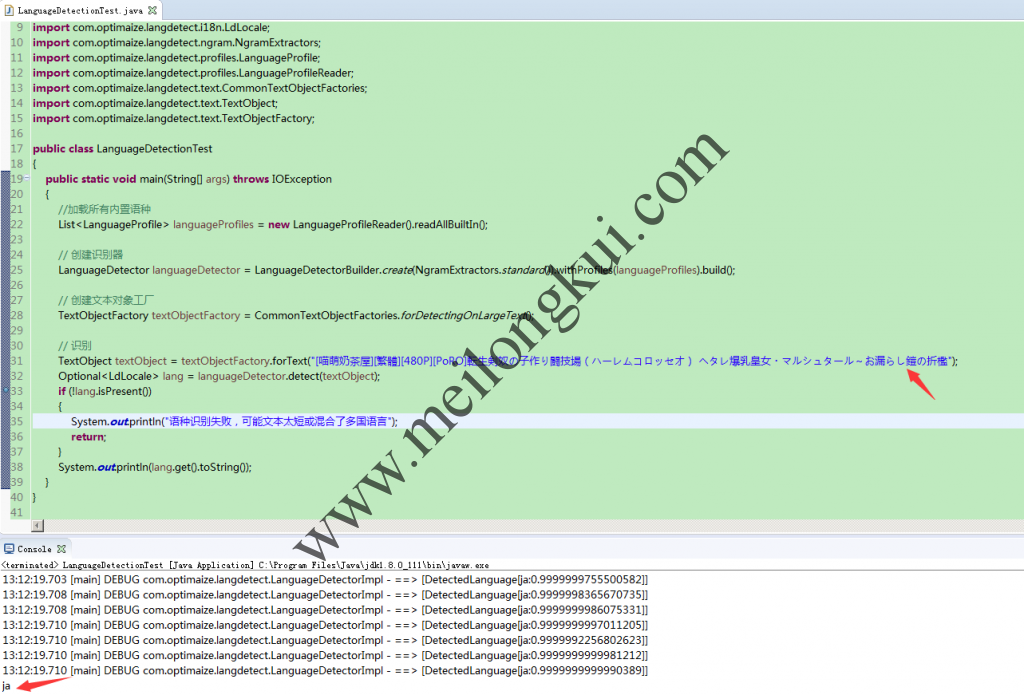
在Java中使用language-detector进行语种识别的结果

com.optimaize.langdetect.LanguageDetector的两个接口
①Optional<LdLocale> detect(CharSequence text);Returns the best detected language if the algorithm is very confident.②List<DetectedLanguage> getProbabilities(CharSequence text);Returns all languages with at least some likeliness.
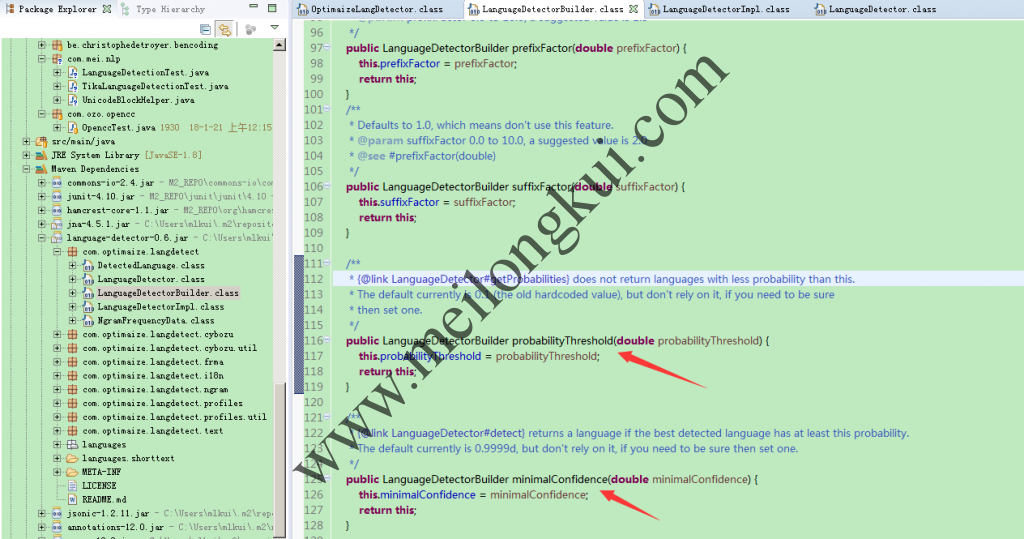
com.optimaize.langdetect.LanguageDetector的两个重要参数
// 概率识别
List<DetectedLanguage> detectedLanguageList = languageDetector.getProbabilities(text);
for (DetectedLanguage detectedLanguage : detectedLanguageList)
{
System.out.println(“概率识别:” + detectedLanguage.getLocale().getLanguage() + “@” + detectedLanguage.getProbability());
}
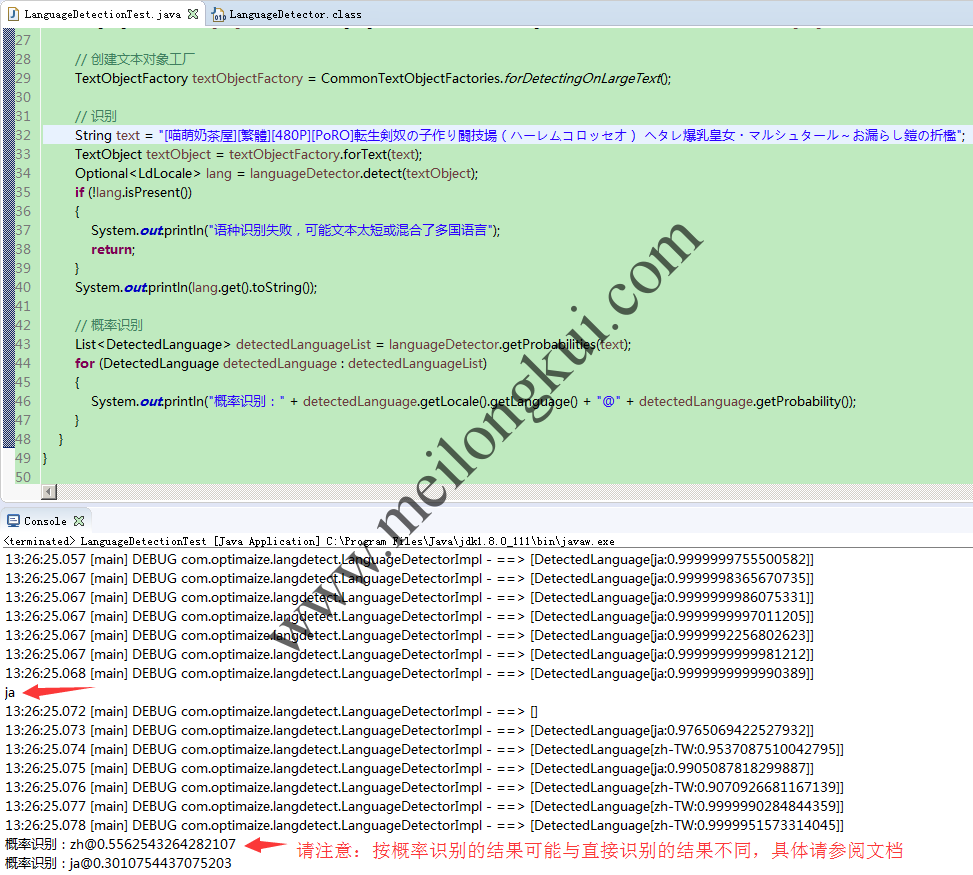
com.optimaize.languagedetector按概率输出识别结果

com.optimaize.languagedetector识别不佳1

com.optimaize.languagedetector识别不佳2

com.optimaize.languagedetector识别不佳3
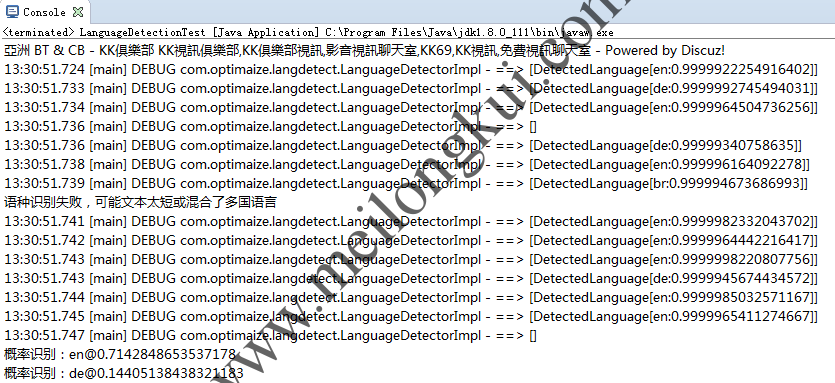
com.optimaize.languagedetector识别不佳4

com.optimaize.languagedetector识别不佳4
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » 使用Java进行语种识别(Language Detection),基于com.optimaize.languagedetector方案