 进城务工人员小梅
进城务工人员小梅在《Hadoop集群搭建(3.1.2)-HDFS》一文中,我们完成了HDFS的搭建,接下来继续搭建基础的MapReduce环境。
一、环境搭建
HDFS主要由NameNode和DataNode组成,而Yarn主要由ResourceManager和NodeManager组成。官网上的标准介绍是:
HDFS daemons are NameNode, SecondaryNameNode, and DataNode. YARN daemons are ResourceManager, NodeManager, and WebAppProxy. If MapReduce is to be used, then the MapReduce Job History Server will also be running. For large installations, these are generally running on separate hosts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<configuration> <!-- Configurations for MapReduce Applications --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- Configurations for MapReduce JobHistory Server --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-master:19888</value> </property> </configuration> |
slave上的为:
|
1 2 3 4 5 6 |
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
请注意,在master的mapred-site.xml中需要配置JobHistory Server,否则会报错。
master和salve上的etc/hadoop/yarn-site.xml相同:
|
1 2 3 4 5 6 7 8 9 10 |
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
在配置了etc/workers后,然后使用sbin中的start-yarn.sh启动yarn集群:
|
1 2 3 4 5 6 7 8 |
root@hadoop001:~/hadoop-3.2.1/sbin# ./start-yarn.sh Starting resourcemanager Starting nodemanagers root@hadoop001:~/hadoop-3.2.1/sbin# jps 7265 ResourceManager 5447 NameNode 5706 SecondaryNameNode 7595 Jps |
可以看到启动的ResourceManager。而在slave上执行jps同样可以看到:
|
1 2 3 4 5 |
root@hadoop003:/usr/lib/java/bin# ./jps 4082 Jps 2260 DataNode 3877 NodeManager root@hadoop003:/usr/lib/java/bin# |
启动的NodeManager。
Yarn ResourceManage的Web端口默认为8088(图中使用跳板机隧道至18088端口):
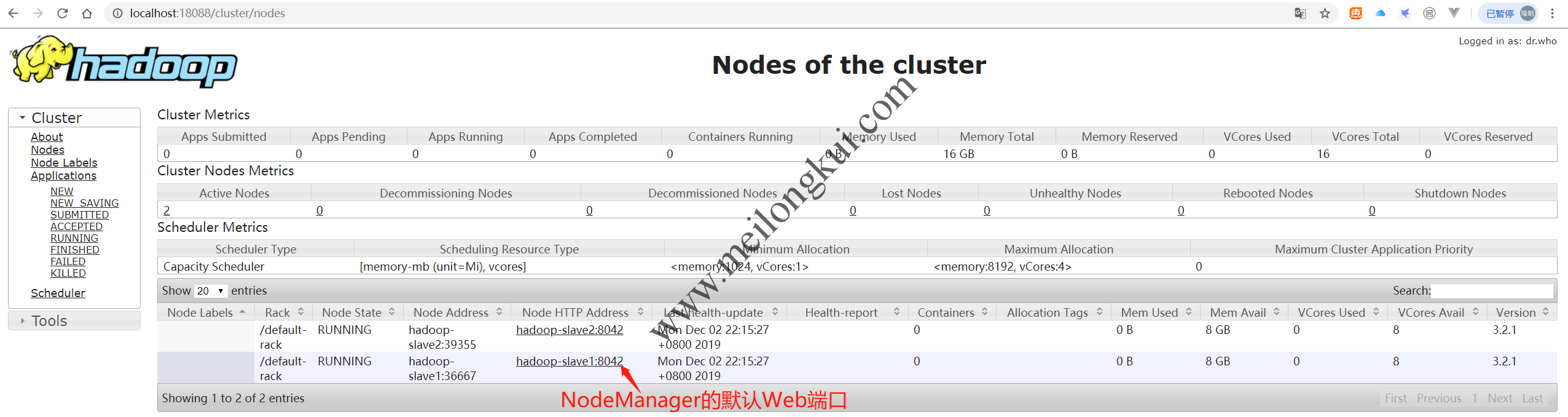
Yarn ResourceManager默认Web Console端口为8088
能够看到两个NodeManager,NodeManager的默认Web Console端口为8043,访问其可以看到NodeManager的详细信息。
我们可以看到,NodeManager的默认Mem为8GB、默认VCores数量为8个。我们可以根据实际物理内存大小及物理CPU的情况,通过在NodeManager的yarn-site.xml中配置yarn.nodemanager.resource.memory-mb和yarn.nodemanager.resource.cpu-vcores进行调整。例如,将NodeManager允许使用的物理内存数量限制为1024MB:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> </configuration> |
此时,我们可以通过Web UI观察到上述变化:
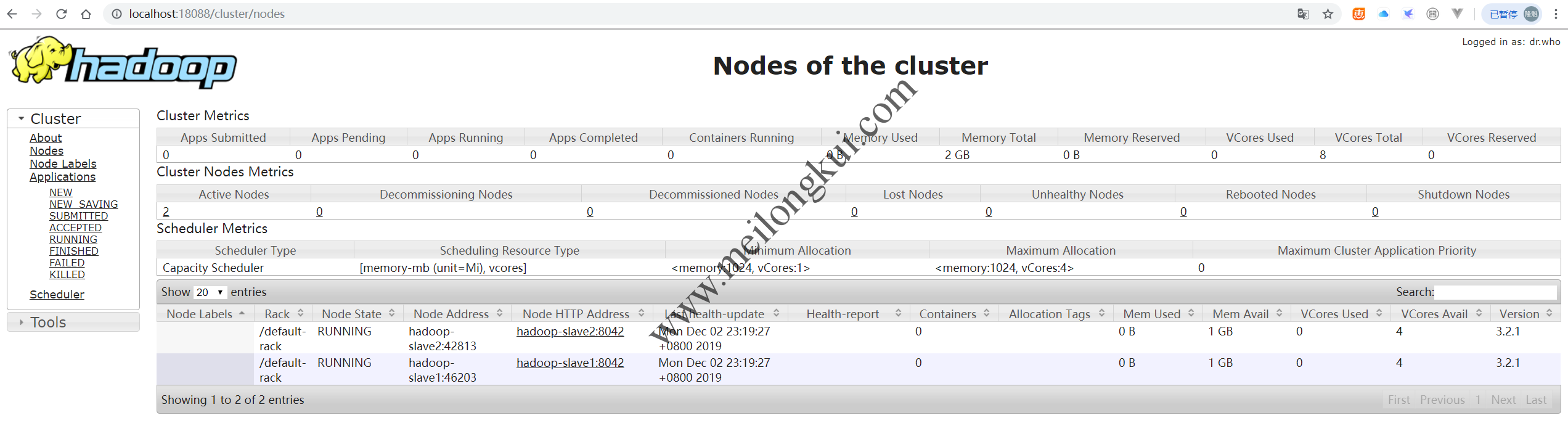
修改NodeManager的资源限制
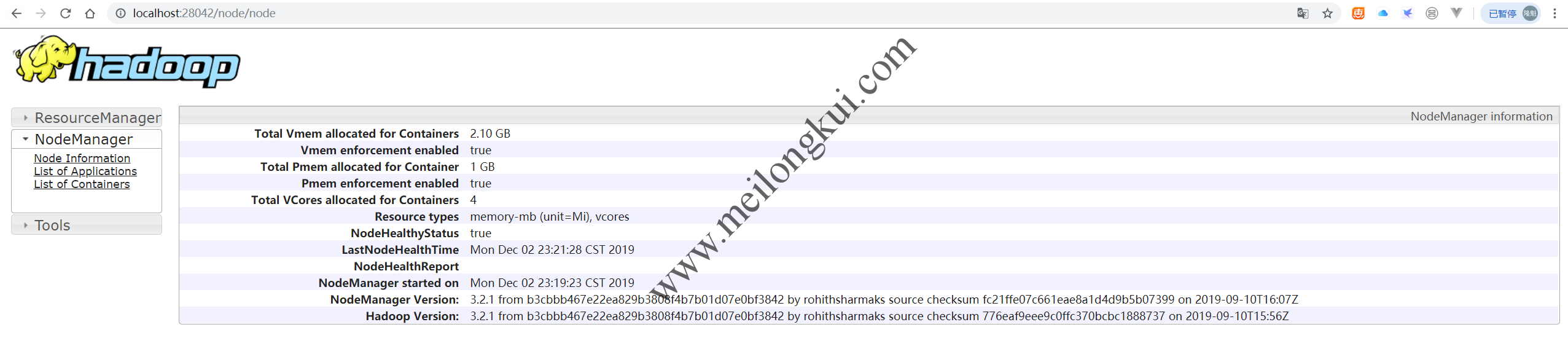
Yarn NodeManger默认端口为8042
二、测试
我们使用最简单的wordcount示例进行测试,该示例位于/root/hadoop-3.2.1/share/hadoop/mapreduce下,名为hadoop-mapreduce-examples-3.2.1.jar。我们先随便找个文件传到hdfs中:
|
1 2 3 4 5 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -put /root/hadoop-3.2.1/logs/hadoop-root-namenode-hadoop001.out /user/input 2019-12-02 23:51:54,421 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -ls /user/input Found 1 items -rw-r--r-- 1 root supergroup 6201 2019-12-02 23:51 /user/input/hadoop-root-namenode-hadoop001.out |
然后使用如下的命令运行测试用例:
|
1 |
hadoop jar /root/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/input/hadoop-root-namenode-hadoop001.out /output |
其中/ouput需要实是hdfs中不存在的目录,程序运行的结果会输出到该目录,若目录存在会报错。
由于我们NodeManager配置的内存仅为1024MB,而默认MapReduce作业所需的最小内存是1536,因此,会报出“Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation.”的错误:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop jar /root/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/input/hadoop-root-namenode-hadoop001.out /output 2019-12-02 23:56:20,003 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.16.0.211:8032 2019-12-02 23:56:21,025 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1575299966262_0001 2019-12-02 23:56:21,249 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-02 23:56:21,464 INFO input.FileInputFormat: Total input files to process : 1 2019-12-02 23:56:21,541 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-02 23:56:21,756 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-02 23:56:21,768 WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:986) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:640) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:810) 2019-12-02 23:56:21,770 INFO mapreduce.JobSubmitter: number of splits:1 2019-12-02 23:56:21,958 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-02 23:56:21,993 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1575299966262_0001 2019-12-02 23:56:21,993 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2019-12-02 23:56:22,316 INFO conf.Configuration: resource-types.xml not found 2019-12-02 23:56:22,316 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2019-12-02 23:56:22,479 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/root/.staging/job_1575299966262_0001 java.io.IOException: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[memory-mb], Requested resource=<memory:1536, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:8192, vCores:4> at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.throwInvalidResourceException(SchedulerUtils.java:491) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.checkResourceRequestAgainstAvailableResource(SchedulerUtils.java:387) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.validateResourceRequest(SchedulerUtils.java:315) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.normalizeAndValidateRequest(SchedulerUtils.java:293) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.validateAndCreateResourceRequest(RMAppManager.java:589) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.createAndPopulateNewRMApp(RMAppManager.java:439) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.submitApplication(RMAppManager.java:374) at org.apache.hadoop.yarn.server.resourcemanager.ClientRMService.submitApplication(ClientRMService.java:690) at org.apache.hadoop.yarn.api.impl.pb.service.ApplicationClientProtocolPBServiceImpl.submitApplication(ApplicationClientProtocolPBServiceImpl.java:290) at org.apache.hadoop.yarn.proto.ApplicationClientProtocol$ApplicationClientProtocolService$2.callBlockingMethod(ApplicationClientProtocol.java:611) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:528) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1070) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:999) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:927) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2915) at org.apache.hadoop.mapred.YARNRunner.submitJob(YARNRunner.java:345) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:251) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588) at org.apache.hadoop.examples.WordCount.main(WordCount.java:87) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:323) at org.apache.hadoop.util.RunJar.main(RunJar.java:236) Caused by: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[memory-mb], Requested resource=<memory:1536, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:8192, vCores:4> at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.throwInvalidResourceException(SchedulerUtils.java:491) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.checkResourceRequestAgainstAvailableResource(SchedulerUtils.java:387) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.validateResourceRequest(SchedulerUtils.java:315) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.normalizeAndValidateRequest(SchedulerUtils.java:293) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.validateAndCreateResourceRequest(RMAppManager.java:589) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.createAndPopulateNewRMApp(RMAppManager.java:439) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.submitApplication(RMAppManager.java:374) at org.apache.hadoop.yarn.server.resourcemanager.ClientRMService.submitApplication(ClientRMService.java:690) at org.apache.hadoop.yarn.api.impl.pb.service.ApplicationClientProtocolPBServiceImpl.submitApplication(ApplicationClientProtocolPBServiceImpl.java:290) at org.apache.hadoop.yarn.proto.ApplicationClientProtocol$ApplicationClientProtocolService$2.callBlockingMethod(ApplicationClientProtocol.java:611) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:528) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1070) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:999) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:927) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2915) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.yarn.ipc.RPCUtil.instantiateException(RPCUtil.java:53) at org.apache.hadoop.yarn.ipc.RPCUtil.instantiateYarnException(RPCUtil.java:75) at org.apache.hadoop.yarn.ipc.RPCUtil.unwrapAndThrowException(RPCUtil.java:116) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.submitApplication(ApplicationClientProtocolPBClientImpl.java:304) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy13.submitApplication(Unknown Source) at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(YarnClientImpl.java:309) at org.apache.hadoop.mapred.ResourceMgrDelegate.submitApplication(ResourceMgrDelegate.java:303) at org.apache.hadoop.mapred.YARNRunner.submitJob(YARNRunner.java:330) ... 22 more Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException): Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[memory-mb], Requested resource=<memory:1536, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:8192, vCores:4> at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.throwInvalidResourceException(SchedulerUtils.java:491) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.checkResourceRequestAgainstAvailableResource(SchedulerUtils.java:387) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.validateResourceRequest(SchedulerUtils.java:315) at org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerUtils.normalizeAndValidateRequest(SchedulerUtils.java:293) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.validateAndCreateResourceRequest(RMAppManager.java:589) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.createAndPopulateNewRMApp(RMAppManager.java:439) at org.apache.hadoop.yarn.server.resourcemanager.RMAppManager.submitApplication(RMAppManager.java:374) at org.apache.hadoop.yarn.server.resourcemanager.ClientRMService.submitApplication(ClientRMService.java:690) at org.apache.hadoop.yarn.api.impl.pb.service.ApplicationClientProtocolPBServiceImpl.submitApplication(ApplicationClientProtocolPBServiceImpl.java:290) at org.apache.hadoop.yarn.proto.ApplicationClientProtocol$ApplicationClientProtocolService$2.callBlockingMethod(ApplicationClientProtocol.java:611) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:528) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1070) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:999) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:927) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2915) at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1545) at org.apache.hadoop.ipc.Client.call(Client.java:1491) at org.apache.hadoop.ipc.Client.call(Client.java:1388) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:233) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:118) at com.sun.proxy.$Proxy12.submitApplication(Unknown Source) at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.submitApplication(ApplicationClientProtocolPBClientImpl.java:301) ... 35 more root@hadoop001:~/hadoop-3.2.1/bin# |
此这是由于我们之前将NodeManager的内存限制为了1024MB,调整为1536MB:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1536</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> </configuration> |
再次运行,报错“ Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster”,完整错误如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
root@hadoop001:~/hadoop-3.2.1/sbin# hadoop jar /root/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount -D mapreduce.map.memory.mb=512 -D mapreduce.reduce.memory.mb=512 -D mapreduce.map.java.opts=-Xmx512m /user/input/hadoop-root-namenode-hadoop001.out /output2019-12-03 10:05:40,233 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.16.0.211:8032 2019-12-03 10:05:41,174 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1575338702976_0001 2019-12-03 10:05:41,379 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 10:05:41,577 INFO input.FileInputFormat: Total input files to process : 1 2019-12-03 10:05:41,640 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 10:05:41,695 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 10:05:41,713 INFO mapreduce.JobSubmitter: number of splits:1 2019-12-03 10:05:41,913 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 10:05:41,949 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1575338702976_0001 2019-12-03 10:05:41,949 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2019-12-03 10:05:42,286 INFO conf.Configuration: resource-types.xml not found 2019-12-03 10:05:42,287 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2019-12-03 10:05:42,673 INFO impl.YarnClientImpl: Submitted application application_1575338702976_0001 2019-12-03 10:05:42,810 INFO mapreduce.Job: The url to track the job: http://hadoop-master:8088/proxy/application_1575338702976_0001/ 2019-12-03 10:05:42,816 INFO mapreduce.Job: Running job: job_1575338702976_0001 2019-12-03 10:05:48,913 INFO mapreduce.Job: Job job_1575338702976_0001 running in uber mode : false 2019-12-03 10:05:48,915 INFO mapreduce.Job: map 0% reduce 0% 2019-12-03 10:05:48,936 INFO mapreduce.Job: Job job_1575338702976_0001 failed with state FAILED due to: Application application_1575338702976_0001 failed 2 times due to AM Container for appattempt_1575338702976_0001_000002 exited with exitCode: 1 Failing this attempt.Diagnostics: [2019-12-03 10:05:48.518]Exception from container-launch. Container id: container_1575338702976_0001_02_000001 Exit code: 1 [2019-12-03 10:05:48.597]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> [2019-12-03 10:05:48.597]Container exited with a non-zero exit code 1. Error file: prelaunch.err. Last 4096 bytes of prelaunch.err : Last 4096 bytes of stderr : Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> For more detailed output, check the application tracking page: http://hadoop-master:8088/cluster/app/application_1575338702976_0001 Then click on links to logs of each attempt. . Failing the application. 2019-12-03 10:05:48,962 INFO mapreduce.Job: Counters: 0 |
可以从RM的Web UI中也可以看到失败:
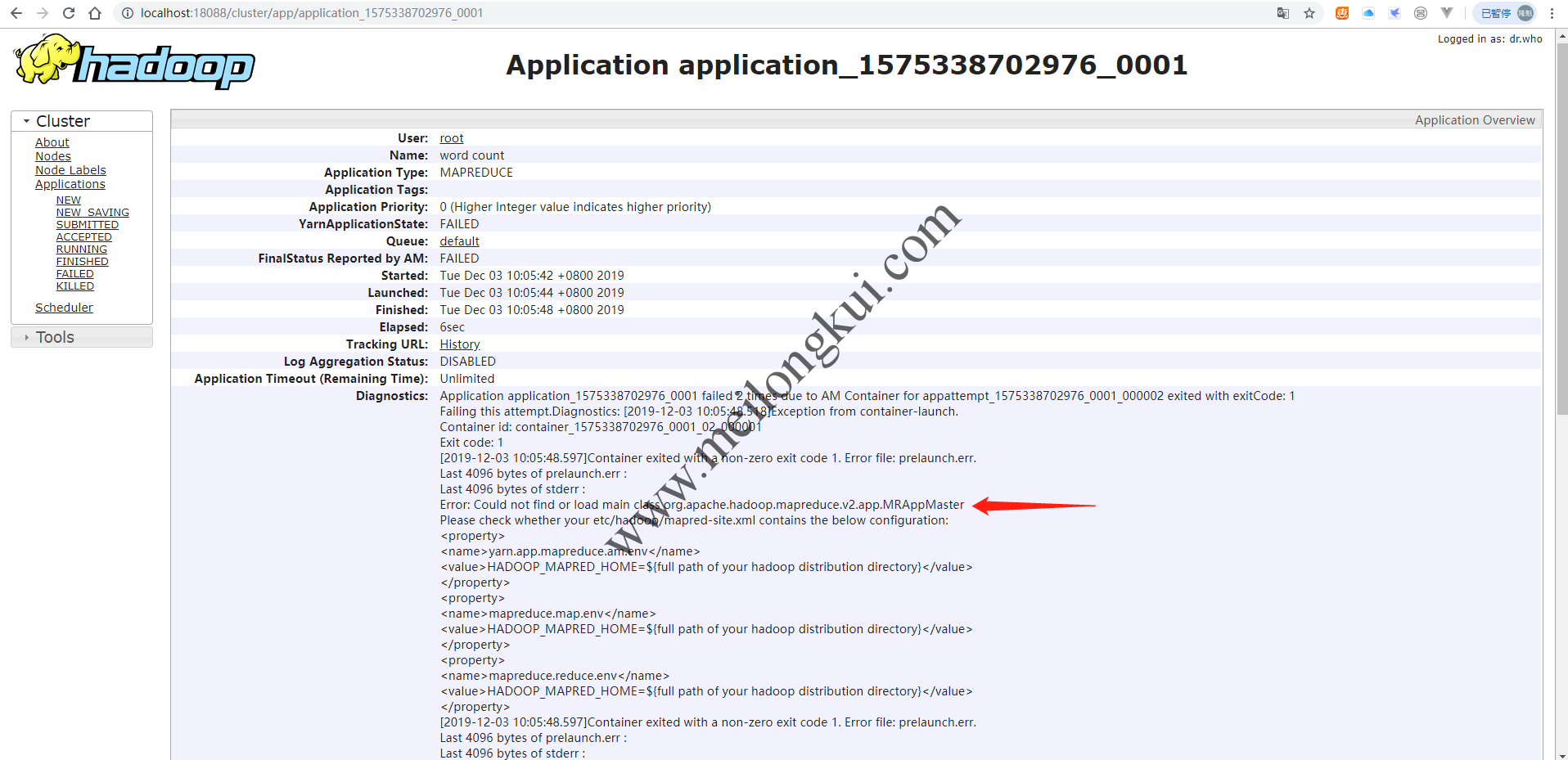
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
根据提示,在所有master和slave的mapred-site.xml中添加如下内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> |
然后重启yarn集群,重新运行刚才的MapReduce程序,成功运行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop jar /root/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/input/hadoop-root-namenode-hadoop001.out /output2 2019-12-03 11:34:22,364 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.16.0.211:8032 2019-12-03 11:34:23,316 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1575343729138_0002 2019-12-03 11:34:23,522 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 11:34:23,706 INFO input.FileInputFormat: Total input files to process : 1 2019-12-03 11:34:23,775 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 11:34:23,830 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 11:34:23,840 INFO mapreduce.JobSubmitter: number of splits:1 2019-12-03 11:34:24,020 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2019-12-03 11:34:24,047 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1575343729138_0002 2019-12-03 11:34:24,047 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2019-12-03 11:34:24,413 INFO conf.Configuration: resource-types.xml not found 2019-12-03 11:34:24,414 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2019-12-03 11:34:24,516 INFO impl.YarnClientImpl: Submitted application application_1575343729138_0002 2019-12-03 11:34:24,574 INFO mapreduce.Job: The url to track the job: http://hadoop-master:8088/proxy/application_1575343729138_0002/ 2019-12-03 11:34:24,574 INFO mapreduce.Job: Running job: job_1575343729138_0002 2019-12-03 11:34:34,755 INFO mapreduce.Job: Job job_1575343729138_0002 running in uber mode : false 2019-12-03 11:34:34,757 INFO mapreduce.Job: map 0% reduce 0% 2019-12-03 11:34:41,835 INFO mapreduce.Job: map 100% reduce 0% 2019-12-03 11:34:48,883 INFO mapreduce.Job: map 100% reduce 100% 2019-12-03 11:34:49,905 INFO mapreduce.Job: Job job_1575343729138_0002 completed successfully 2019-12-03 11:34:50,054 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=5848 FILE: Number of bytes written=463717 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=6338 HDFS: Number of bytes written=5306 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=1 Launched reduce tasks=1 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=4166 Total time spent by all reduces in occupied slots (ms)=4562 Total time spent by all map tasks (ms)=4166 Total time spent by all reduce tasks (ms)=4562 Total vcore-milliseconds taken by all map tasks=4166 Total vcore-milliseconds taken by all reduce tasks=4562 Total megabyte-milliseconds taken by all map tasks=4265984 Total megabyte-milliseconds taken by all reduce tasks=4671488 Map-Reduce Framework Map input records=35 Map output records=242 Map output bytes=6965 Map output materialized bytes=5848 Input split bytes=137 Combine input records=242 Combine output records=130 Reduce input groups=130 Reduce shuffle bytes=5848 Reduce input records=130 Reduce output records=130 Spilled Records=260 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=223 CPU time spent (ms)=1240 Physical memory (bytes) snapshot=331083776 Virtual memory (bytes) snapshot=4226375680 Total committed heap usage (bytes)=170004480 Peak Map Physical memory (bytes)=216829952 Peak Map Virtual memory (bytes)=2109808640 Peak Reduce Physical memory (bytes)=114253824 Peak Reduce Virtual memory (bytes)=2116567040 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=6201 File Output Format Counters Bytes Written=5306 root@hadoop001:~/hadoop-3.2.1/bin# |
我们可以使用如下的命令来查看结果:
|
1 2 3 4 5 |
root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -ls /output2 Found 2 items -rw-r--r-- 1 root supergroup 0 2019-12-03 11:34 /output2/_SUCCESS -rw-r--r-- 1 root supergroup 5306 2019-12-03 11:34 /output2/part-r-00000 root@hadoop001:~/hadoop-3.2.1/bin# hadoop fs -cat /output2/* |
至此,基本的Hadoop完全分布式集群搭建完毕。
参考资料:
1、https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-common/ClusterSetup.html,其中明确了各个参数的含义;
2、https://kontext.tech/column/hadoop/267/configure-yarn-and-mapreduce-resources-in-hadoop-cluster
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Hadoop完全分布式集群搭建(3.2.1)-MapReduce+Yarn