 进城务工人员小梅
进城务工人员小梅在开发中,针对Seata 1.4.0 Server的数据库进行分库分表时,发现其transaction_id总是被1024整除,导致数据总是会被插入到第0张表中。本来以为,Seata使用的是Snowflake算法生成的分布式序列号,在直觉上应该是均匀的(如果不做分库分表是一点问题没有),出现transaction_id总是被1024整除的现象很诡异,遂看其实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 |
package io.seata.common.util; import java.net.InetAddress; import java.net.UnknownHostException; /** * @author funkye */ public class IdWorker { private volatile static IdWorker idWorker = null; /** * Start time cut (2020-05-03) */ private final long twepoch = 1588435200000L; /** * The number of bits occupied by the machine id */ private final long workerIdBits = 10L; /** * Maximum supported machine id, the result is 1023 (this shift algorithm can quickly calculate the largest decimal * number that can be represented by a few binary numbers) */ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** * The number of bits the sequence occupies in id */ private final long sequenceBits = 12L; /** * Machine ID left 12 digits */ private final long workerIdShift = sequenceBits; /** * Time truncated to the left by 22 bits (10 + 12) */ private final long timestampLeftShift = sequenceBits + workerIdBits; /** * Generate sequence mask */ private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** * Machine ID (0 ~ 1023) */ private long workerId; /** * Sequence in milliseconds (0 ~ 4095) */ private long sequence = 0L; /** * Time of last ID generation */ private long lastTimestamp = -1L; /** * Constructor * * @param workerId * Job ID (0 ~ 1023) */ public IdWorker(long workerId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException( String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } this.workerId = workerId; } /** * Get the next ID (the method is thread-safe) * * @return SnowflakeId */ public synchronized long nextId() { long timestamp = timeGen(); if (timestamp < lastTimestamp) { throw new RuntimeException(String.format( "clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { sequence = 0L; } lastTimestamp = timestamp; return ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence; } /** * Block until the next millisecond until a new timestamp is obtained * * @param lastTimestamp * Time of last ID generation * @return Current timestamp */ protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /** * Returns the current time in milliseconds * * @return Current time (ms) */ protected long timeGen() { return System.currentTimeMillis(); } public static IdWorker getInstance() { if (idWorker == null) { synchronized (IdWorker.class) { if (idWorker == null) { init(initWorkerId()); } } } return idWorker; } public static long initWorkerId() { InetAddress address; try { address = InetAddress.getLocalHost(); } catch (final UnknownHostException e) { throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!",e); } byte[] ipAddressByteArray = address.getAddress(); return ((ipAddressByteArray[ipAddressByteArray.length - 2] & 0B11) << Byte.SIZE) + (ipAddressByteArray[ipAddressByteArray.length - 1] & 0xFF); } public static void init(Long serverNodeId) { if (idWorker == null) { synchronized (IdWorker.class) { if (idWorker == null) { idWorker = new IdWorker(serverNodeId); } } } } } |
Seata Server启动的时候会通过命令行参数传入一个long类型的ServerNode,最终通过UUIDGenerator调到IdWorker,并通过nextId获取一个全局序列号用于区分每一个分布式事务。
Snowflake算法是一种以划分命名空间来生成ID的一种算法,这种方案把64-bit分别划分成多段,分别表示机器、时间、序号等:

其中:
1、时间戳是从当前毫秒时间到某个时间的增量,通常使用41bit来表示,因此可以覆盖(1L<<41)/(1000L*3600*24*365)=69年;
2、10bit的worker可以表示1024台机器;
3、12位自增序列号可以允许在同一个毫秒内容纳2^12个序号;
性能:
1、保证在任何一个IDC的任何一个实例在任意毫秒内生成的ID都是不同的;
2、理论最高QPS为409.6w/s(2^12*1000);
优势:
1、毫秒数在高位,自增序列在低位,整个ID都是趋势递增的;
2、不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也非常高;
3、可以根据自身业务特性分配比特位,非常灵活;
缺点:
1、强依赖机器时钟,如果机器上的时钟回拨,会导致发号重复或者服务会处于不可用状态;
显然,由于:
|
1 |
((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence = ((timestamp - twepoch) << timestampLeftShift) + (workerId << workerIdShift) + sequence; |
只要((timestamp – twepoch) << timestampLeftShift)、(workerId << workerIdShift)、sequence都可以被1024整除那么序列号就可以被1024整除。由于timestampLeftShift+workerIdShift=12+10=22、workerIdShift=12、sequence从0开始,因此只要获取序列号时跨毫秒,那么workerIdShift的12个算数左移就决定了得到的结果一定能够被2^10=1024整除(实际上是被2的1-12次方整除)。
不放心的话可以代码验证:
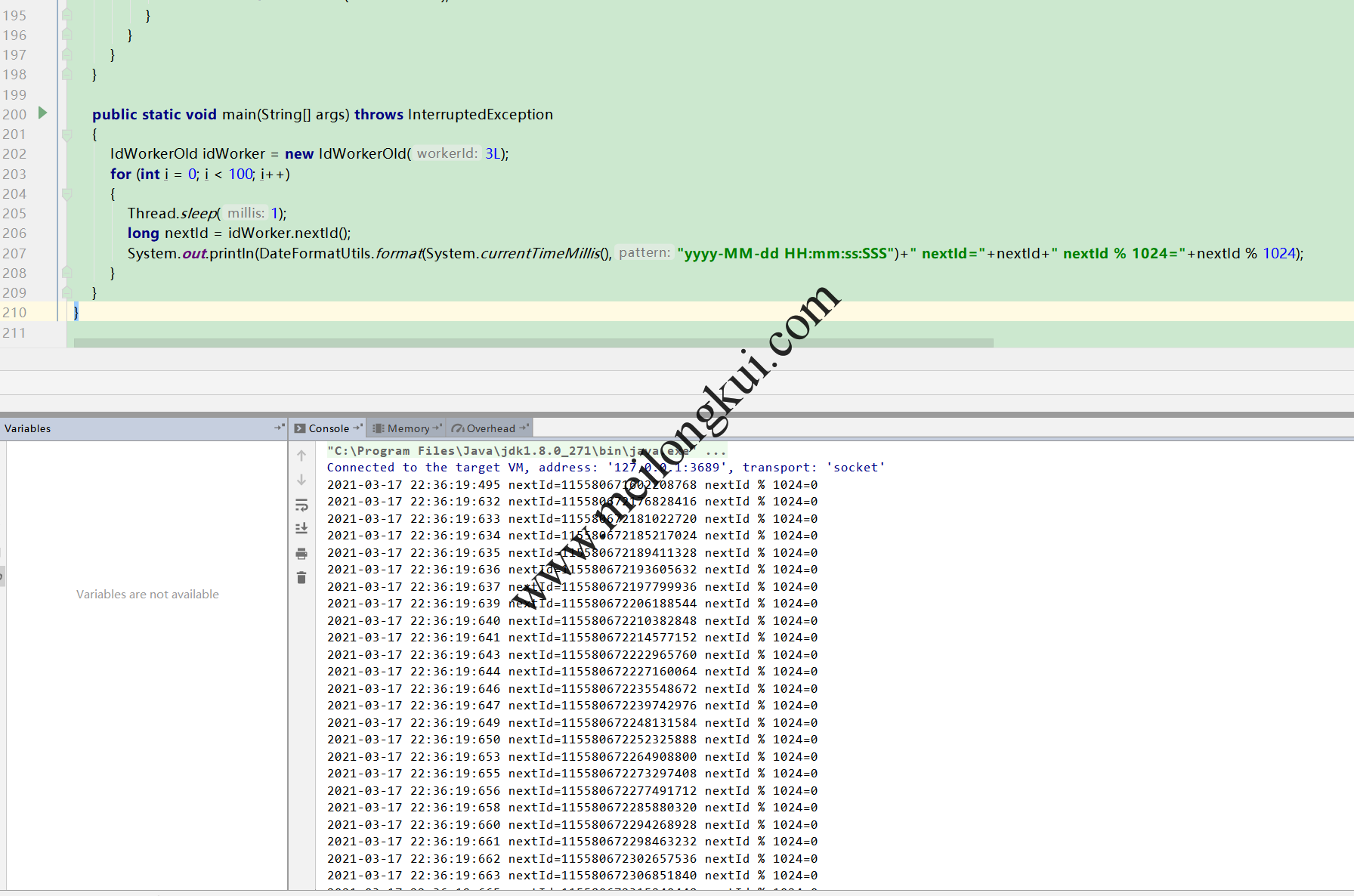
如果不切毫秒时间戳的话,则可以观察到序列号递增:
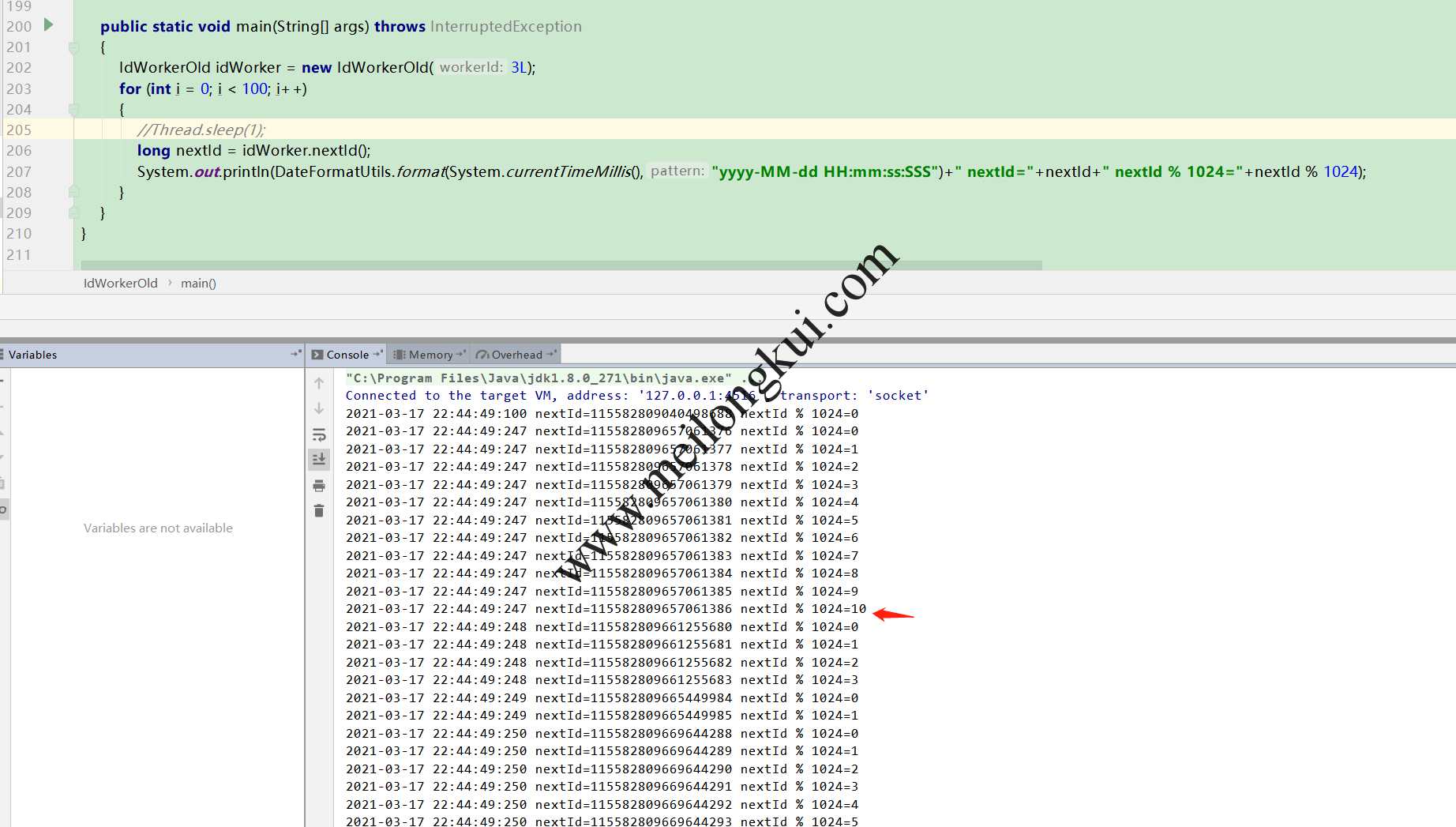
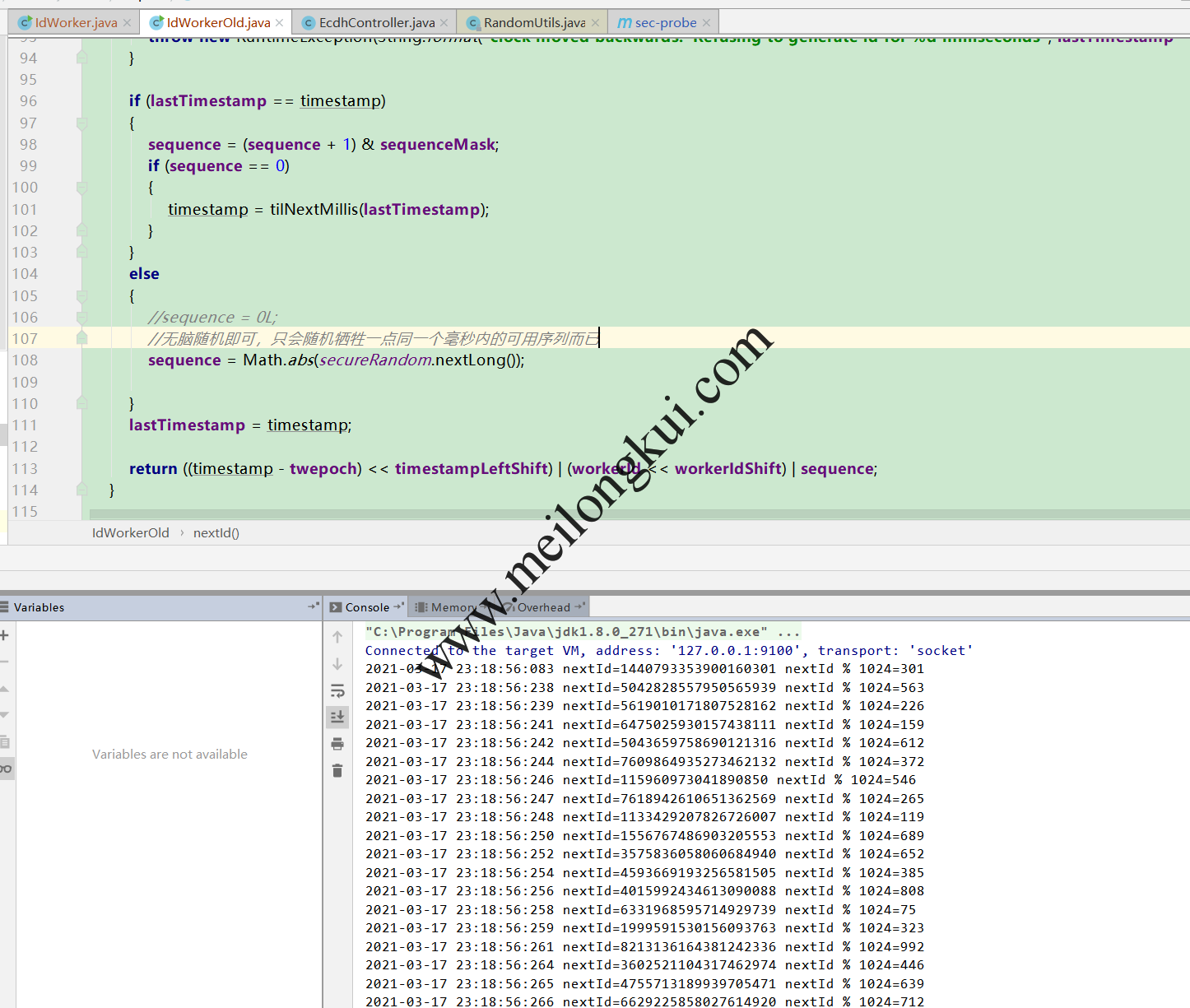
硬要解决这个问题的话比较简单,让sequence不要每次切换毫秒后从0开始就行了,在合理范围内随机,不过会牺牲一些序列(实际远远够用了):
在翻GitHub的时候发现1.4.0以后master分支对上述Snowflake进行了调整:
换了一种实现,改成了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
package io.seata.common.util; import java.net.NetworkInterface; import java.util.Enumeration; import java.util.Random; import java.util.concurrent.atomic.AtomicLong; /** * @author funkye * @author selfishlover */ public class IdWorker { /** * Start time cut (2020-05-03) */ private final long twepoch = 1588435200000L; /** * The number of bits occupied by workerId */ private final int workerIdBits = 10; /** * The number of bits occupied by timestamp */ private final int timestampBits = 41; /** * The number of bits occupied by sequence */ private final int sequenceBits = 12; /** * Maximum supported machine id, the result is 1023 */ private final int maxWorkerId = ~(-1 << workerIdBits); /** * business meaning: machine ID (0 ~ 1023) * actual layout in memory: * highest 1 bit: 0 * middle 10 bit: workerId * lowest 53 bit: all 0 */ private long workerId; /** * timestamp and sequence mix in one Long * highest 11 bit: not used * middle 41 bit: timestamp * lowest 12 bit: sequence */ private AtomicLong timestampAndSequence; /** * mask that help to extract timestamp and sequence from a long */ private final long timestampAndSequenceMask = ~(-1L << (timestampBits + sequenceBits)); /** * instantiate an IdWorker using given workerId * @param workerId if null, then will auto assign one */ public IdWorker(Long workerId) { initTimestampAndSequence(); initWorkerId(workerId); } /** * init first timestamp and sequence immediately */ private void initTimestampAndSequence() { long timestamp = getNewestTimestamp(); long timestampWithSequence = timestamp << sequenceBits; this.timestampAndSequence = new AtomicLong(timestampWithSequence); } /** * init workerId * @param workerId if null, then auto generate one */ private void initWorkerId(Long workerId) { if (workerId == null) { workerId = generateWorkerId(); } if (workerId > maxWorkerId || workerId < 0) { String message = String.format("worker Id can't be greater than %d or less than 0", maxWorkerId); throw new IllegalArgumentException(message); } this.workerId = workerId << (timestampBits + sequenceBits); } /** * get next UUID(base on snowflake algorithm), which look like: * highest 1 bit: always 0 * next 10 bit: workerId * next 41 bit: timestamp * lowest 12 bit: sequence * @return UUID */ public long nextId() { waitIfNecessary(); long next = timestampAndSequence.incrementAndGet(); long timestampWithSequence = next & timestampAndSequenceMask; return workerId | timestampWithSequence; } /** * block current thread if the QPS of acquiring UUID is too high * that current sequence space is exhausted */ private void waitIfNecessary() { long currentWithSequence = timestampAndSequence.get(); long current = currentWithSequence >>> sequenceBits; long newest = getNewestTimestamp(); if (current >= newest) { try { Thread.sleep(5); } catch (InterruptedException ignore) { // don't care } } } /** * get newest timestamp relative to twepoch */ private long getNewestTimestamp() { return System.currentTimeMillis() - twepoch; } /** * auto generate workerId, try using mac first, if failed, then randomly generate one * @return workerId */ private long generateWorkerId() { try { return generateWorkerIdBaseOnMac(); } catch (Exception e) { return generateRandomWork |
上述改过的全局事务ID与之前的Snowflake算法略有不同,其结构为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
/** * get next UUID(base on snowflake algorithm), which look like: * highest 1 bit: always 0 * next 10 bit: workerId * next 41 bit: timestamp * lowest 12 bit: sequence * @return UUID */ public long nextId() { waitIfNecessary(); long next = timestampAndSequence.incrementAndGet(); long timestampWithSequence = next & timestampAndSequenceMask; return workerId | timestampWithSequence; } /** * block current thread if the QPS of acquiring UUID is too high * that current sequence space is exhausted */ private void waitIfNecessary() { long currentWithSequence = timestampAndSequence.get(); long current = currentWithSequence >>> sequenceBits; long newest = getNewestTimestamp(); if (current >= newest) { try { Thread.sleep(5); } catch (InterruptedException ignore) { // don't care } } } |
很明显把WorkerId放在了最前面,然后用AtomicLong实现了序列递增(初始值用的是当前时间戳),跑一下长这样:
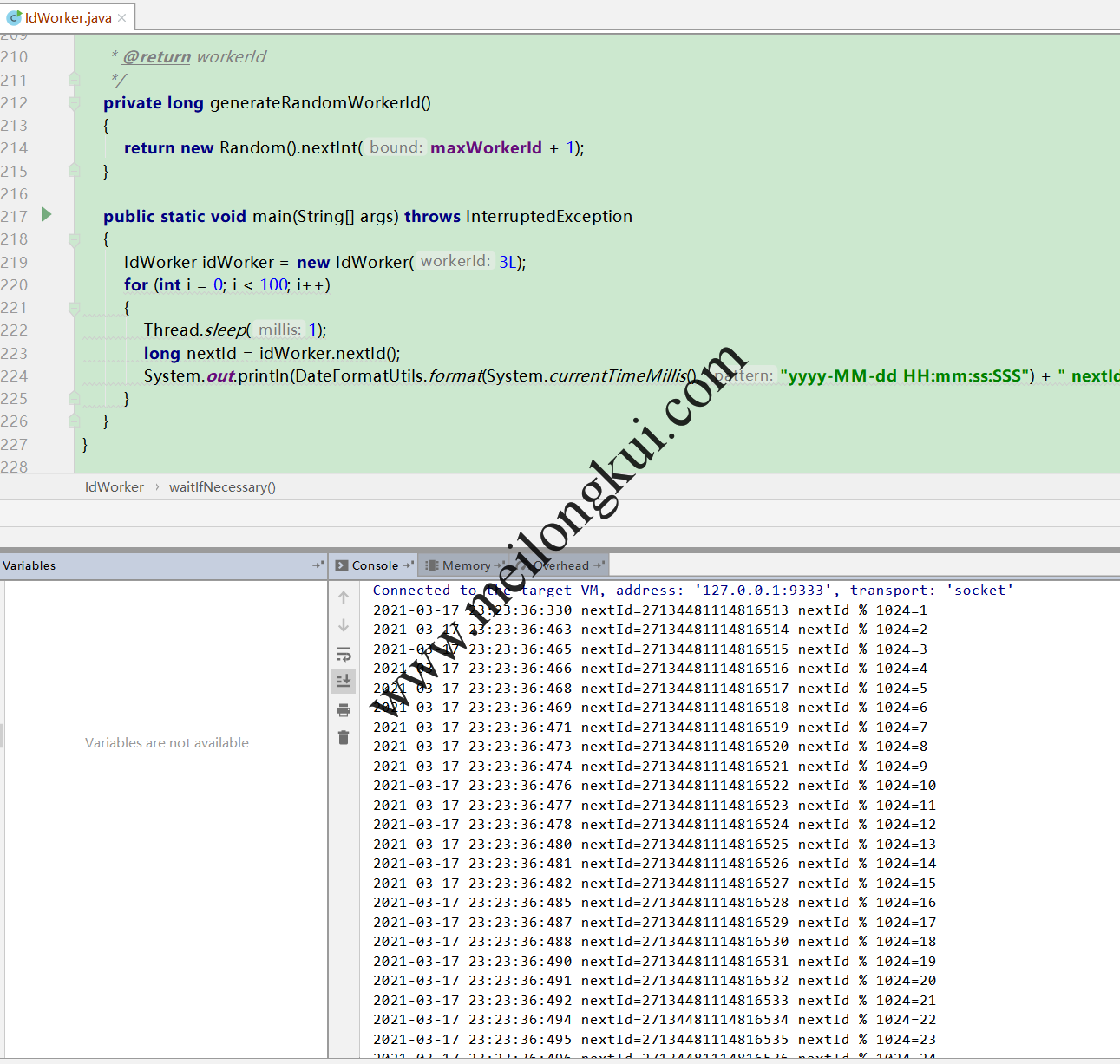
不过,这样,毫秒时间戳的随机性就只在初始化时有用了,本质上退化成了利用前十位WorkerId区分了每一个实例,然后每个实例维护一个递增序列,用作全局事务ID没有任何问题,拿来做分库分表也没有问题。由于初始化时sequence从0开始,所以每次启动后对1024取模后都是从1开始的:
|
1 2 3 4 5 6 7 8 |
/** * init first timestamp and sequence immediately */ private void initTimestampAndSequence() { long timestamp = getNewestTimestamp(); long timestampWithSequence = timestamp << sequenceBits; this.timestampAndSequence = new AtomicLong(timestampWithSequence); } |
但如果是从分布式序列号的角度看,由于毫秒时间戳不在最前貌似也不再是趋势递增的了。当然了,是否有必要保持递增趋势的需要看具体的业务场景。
参考文档:
1、https://tech.meituan.com/2017/04/21/mt-leaf.html
转载时请保留出处,违法转载追究到底:进城务工人员小梅 » Seata 1.4.0分布式事务全局唯一序列号总是被1024整除的问题